BudouX は、ウェブをはじめさまざまなプラットフォームで読みやすいテキスト折り返し(改行)を実現するための、軽量な分かち書き器です。オープンソース プロジェクトとして GitHub で公開されており、現時点では日本語と中国語(簡体字、繁体字)をサポートしています。2016 年に公開した Budou の後継となるものですが、Budou とは違いサードパーティの API や分かち書きライブラリに依存せずに動作します。分かち書きのための機械学習モデルを含めて 20 KB 程度に収まるため、ウェブブラウザに配信する JavaScript ファイルに同梱することも可能です。
単語と単語の間をスペースで空けて書く英語などの言語と異なり、日本語や中国語をはじめとするアジア圏の一部の言語は分かち書きをしません。そのため、ウェブサイトやモバイル アプリケーションで日本語や中国語を表示する際に、スクリーンサイズによって好ましくない折り返しが起きてしまうことがあります。このような問題の解決策として、改行要素や改行可能要素を挿入する、特定の要素の折り返しを禁止するなどの方法が考えられます。しかし、そのいずれも対象言語に精通した人物による手作業が必要になるため、大量のテキストがある場合に対応するのは困難です。
この問題を自動で解決するために開発されたのが、BudouX です。BudouX は文字の N グラムに対して AdaBoost アルゴリズムを適用した機械学習モデルを利用しています。この機械学習モデルはテキスト中の各文字について、次の文字の間で区切るべきか否かの二値分類問題を考えます。予測値が正であれば区切り、そうでなければ区切らないという処理を繰り返すことで、読みやすく分かち書きされたテキストを出力します。
特徴量として文字の N グラム(特定の文字が連続して出現するまとまり)のみを使うため、任意の言語に対してモデルを学習、適用できます(Language Neutral)。また、AdaBoost アルゴリズムによって、読みやすい折り返しに強く寄与する N グラムから順に重みを割り当て、それ以外の特徴量は無視できるため、機械学習モデルの軽量化が可能です(Small)。BudouX では JSON シリアライズされた機械学習モデル、すなわち N グラムと重みのペアをデコードして、現れた N グラムに対応する重みの値を足し合わせるだけで予測値が得られます。したがって JSON パーサと基本的な処理構文さえあれば実行できるため、さまざまなプログラミング言語やプラットフォームに容易に拡張することができます(Standalone)。BudouX はこのように Small, Standalone, Language Neutral の 3 つを基本的な方針として開発を進めています。
日本語のデフォルトの分かち書きモデルは、単語単位ではなく文節単位の分ち書きを提供します。これは文節間の改行が日本語の読みやすさに寄与すると考えているためです。このモデルの学習には主に KNB コーパス(Kyoto-University and NTT Blog コーパス)による文節区切りの文章を用いています。モデル訓練の詳細については BudouX scripts README をご覧ください。
現在、BudouX の公式レポジトリでは JavaScript, Python, Java をサポートしています。それぞれの使い方を簡単に紹介します。
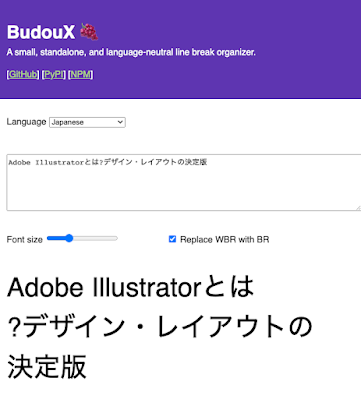
JavaScript
NPM を使う場合、BudouX の JavaScript モジュールは npm i budoux としてインストールできます。日本語のデフォルトの分かち書き器を使う場合は、下記のようにしてパーサを読み込み、処理したい文字列をその parse メソッドに渡します。結果は分かち書きされた文字列の配列が渡されます。
import { loadDefaultJapaneseParser } from 'budoux' ; const parser = loadDefaultJapaneseParser(); console.log(parser.parse('今日は天気です。')); // ['今日は', '天気です。']
NPM を使わず、ウェブブラウザ上で下記のように ES Module として直接読み込むことも可能です。ここではビルドされたモジュールをホストするサイトとして unpkg.com を使用した例を示します。
<script type="module"> import {loadDefaultJapaneseParser} from 'https://unpkg.com/budoux/module/index.js'; const parser = loadDefaultJapaneseParser(); console.log(parser.parse('今日は天気です。')); // ['今日は', '天気です。'] </script>
ウェブでの利用を目的としている場合は、Web Components 版も利用可能です。まずウェブページ内で、下記のようにして BudouX カスタム要素を読み込みます。ここでは例として日本語モデル(budoux-ja)を読み込んでいます。
<script src="https://unpkg.com/budoux/bundle/budoux-ja.min.js"></script>
その後、BudouX により折り返し処理を適用したい文字列を budoux-ja カスタム要素に渡すと、自動でテキスト折り返しを整えるためのマークアップが Shadow Root に挿入されます。
<budoux-ja>今日は天気です。</budoux-ja>
<!-- Shadow Root -->
<span style="word-break: keep-all; overflow-wrap: anywhere;">今日は<wbr>天気です。</span>
Python
BudouX モジュールは、 pip install budoux としてインストールできます。以下に、Python で日本語モデルを読み込み、分かち書きを行う例を示します。
import budoux
parser = budoux.load_default_japanese_parser()
print(parser.parse('今日は天気です。')) # ['今日は', '天気です。']
Java
BudouX モジュールは Maven Central Repository にて com.google.budoux として公開されています。インストール後、以下のようにして日本語モデルを利用できます。
import com.google.budoux.Parser;
public class App {
public static void main(String[] args ){
Parser parser = Parser.loadDefaultJapaneseParser();
System.out.println(parser.parse("今日は天気です。"));
// ["今日は", "天気です。"]
}
BudouX はプレーンテキストだけではなく、HTML コードに対しても適用可能です。より進んだ使い方について詳しくは BudouX レポジトリの README をご覧ください。
ここからは、BudouX をご活用いただいているアドビの Japan R&D に所属する Software Development Engineer の吉田さんに活用の経緯などをお伺いしました。
どこで BudouX を活用している?
自社のオウンドメディアである adobe.com の日本語サイトにて BudouX を活用しています。適切な改行処理を行うことでデバイスサイズに限らずに読みやすい日本語になるように工夫しています。
BudouX を活用しているページの例
https://www.adobe.com/jp/acrobat/online/ppt-to-pdf.html https://business.adobe.com/jp/resources/main.html https://business.adobe.com/jp/customer-success-stories.html
BudouX を活用に至るまでの経緯
実は BudouX 採用前からアドビでは日本語の改行処理に力を入れていました。adobe.com は自社製品の CMS、Adobe Experience Manager 上で構築されていますが、ページを編集する際に区切り文字をマニュアルで入れることで著者が改行ポイントを設定することができました。我々は以前から日本語における適切な改行処理に関心があったというわけです。 話は本題へと移ります。現在 adobe.com は Adobe Experience Manager で構築された従来のサイトから、次世代のアドビの CMS 製品である AEM Franklin をベースにしたサイトへの移行プロジェクトを実施しています。AEM Franklin では Google Docs や Microsoft Word をオーサリング ツールとして活用することができます、また、Adobe Experience Manager で課題であった複雑なシステム構成やウェブサイトのパフォーマンスなどを容易に改善することができる等、新しいコンセプトの製品となっています。 しかし AEM Franklin をベースとした新しい製品を活用したウェブサイトへの移行となったため、今まで存在していた編集時の日本語の改行処理の機能がなくなってしまいました。このような状況の中で、この問題の解決のためにさまざまな手法を検討し、実装コストや運用コストなどを考慮した結果、サーバーサイドで分かち書きなどの前処理するのではなく、クライアントサイドだけで軽量に動作する BudouX がベストだという結論に至り、採用することとなりました。 それでも導入の際には 3 つ課題がありました。1 つ目は BudouX の日本語のデフォルト モデルはアドビのコンテンツを学習していません。特に「お、ご、などの尊敬語に弱い」、「デジタルエクスペリエンスプラットフォームなどの長いカタカナの複合名詞」は精度の面でやや不安があったわけです。そこで新たに adobe.com のデータをスクレイピングし学習させることでよりアドビのサイトにあったモデルを開発することができました。詳しい話はこちらの記事で書かれているので興味がある方はご覧ください。 2 つ目は禁則処理の問題です。禁則処理とは行頭や行末に特定の文字が来ないように文字の並びを調整する処理を指します。例えば、句読点は行頭には来ないようにするなどが挙げられます。BudouX は次の文字の間で区切るべきか否かの二値分類問題を考えています。その結果、かなり低確率ではありますが、周辺文字の状況によって句読点の前で文字が区切られてしまう例がわずかに見られました。我々が普段 HTML で文章を書いているときはブラウザが自動で日本語の禁則処理をしてくれるので問題ありませんが、BudouX では改行ポイントを <wbr> でコントロールしているので、例えば以下の画像のように行頭に疑問符(半角)が来てしまいます。この問題を解決するために、我々はルールベースの禁則処理を BudouX に追加することで禁則処理を実現しました。なお、この問題は現在 BudouX の GitHub にイシューとして登録しています。
実は BudouX 採用前からアドビでは日本語の改行処理に力を入れていました。adobe.com は自社製品の CMS、Adobe Experience Manager 上で構築されていますが、ページを編集する際に区切り文字をマニュアルで入れることで著者が改行ポイントを設定することができました。我々は以前から日本語における適切な改行処理に関心があったというわけです。
話は本題へと移ります。現在 adobe.com は Adobe Experience Manager で構築された従来のサイトから、次世代のアドビの CMS 製品である AEM Franklin をベースにしたサイトへの移行プロジェクトを実施しています。AEM Franklin では Google Docs や Microsoft Word をオーサリング ツールとして活用することができます、また、Adobe Experience Manager で課題であった複雑なシステム構成やウェブサイトのパフォーマンスなどを容易に改善することができる等、新しいコンセプトの製品となっています。
しかし AEM Franklin をベースとした新しい製品を活用したウェブサイトへの移行となったため、今まで存在していた編集時の日本語の改行処理の機能がなくなってしまいました。このような状況の中で、この問題の解決のためにさまざまな手法を検討し、実装コストや運用コストなどを考慮した結果、サーバーサイドで分かち書きなどの前処理するのではなく、クライアントサイドだけで軽量に動作する BudouX がベストだという結論に至り、採用することとなりました。
それでも導入の際には 3 つ課題がありました。1 つ目は BudouX の日本語のデフォルト モデルはアドビのコンテンツを学習していません。特に「お、ご、などの尊敬語に弱い」、「デジタルエクスペリエンスプラットフォームなどの長いカタカナの複合名詞」は精度の面でやや不安があったわけです。そこで新たに adobe.com のデータをスクレイピングし学習させることでよりアドビのサイトにあったモデルを開発することができました。詳しい話はこちらの記事で書かれているので興味がある方はご覧ください。
2 つ目は禁則処理の問題です。禁則処理とは行頭や行末に特定の文字が来ないように文字の並びを調整する処理を指します。例えば、句読点は行頭には来ないようにするなどが挙げられます。BudouX は次の文字の間で区切るべきか否かの二値分類問題を考えています。その結果、かなり低確率ではありますが、周辺文字の状況によって句読点の前で文字が区切られてしまう例がわずかに見られました。我々が普段 HTML で文章を書いているときはブラウザが自動で日本語の禁則処理をしてくれるので問題ありませんが、BudouX では改行ポイントを <wbr> でコントロールしているので、例えば以下の画像のように行頭に疑問符(半角)が来てしまいます。この問題を解決するために、我々はルールベースの禁則処理を BudouX に追加することで禁則処理を実現しました。なお、この問題は現在 BudouX の GitHub にイシューとして登録しています。
3 つ目はウェブサイトのコンテンツの著者の期待通りに改行処理されていない場合にどうするか? BudouX は高い精度で読みやすい単位に改行処理を行ってくれます。しかし、軽量さやスピードを重視しているので、ときには著者が意図する挙動と違う出力をしてしまうことがありました。また、どれだけ高い精度のモデルを採用したとしても、完全自動では 100% 著者の意図通りの結果を出すことは不可能です。どうしてもコンテンツを運用していく中でここだけは間違えてほしくないという場面は存在するわけです。そこで我々は自動+マニュアルの微調整を可能にすることでこれを解決しました。 幸いなことに AEM Franklin にはオーサリング ツールである Google Docs と Microsoft Word のファイルに対してウェブサイトのページごと、またはすべてのページに細かいメタデータを追加する機能が備わっていました。この機能を活用することで、著者が期待するルールや設定を細かく追加できるようになりました。例えば以下のようなことが可能となっています。 " ご覧ください " というテキストがあったときに " ご " と " 覧ください " の間では改行できないようにする " カスタマージャーニーマップ " というテキストがあったときに " カスタマー " と " ジャーニーマップ " の間で改行できるようにする ページの一部分に BudouX を適用しないようにする BudouX に渡すパラメータを調整する この結果 BudouX のスマートな自動改行処理のベネフィットを受けつつ、著者が細かい微調整を加えることを可能にし、理想な運用体制を構築の実現に成功しました。また、現在では移行前の Adobe Experience Manager で管理されているページでも BudouX は活用されており、マニュアルで実施していた改行処理は自動化されています。 BudouX はその軽量さとパフォーマンスが売りです。Lighthouse のスコアへの影響も軽微なもので、adobe.com のパフォーマンス メトリクスをクリアしています。また、最近では finetune が可能になり個別のサイトのコンテンツにあったモデルをより簡単に開発できるようになりました。今後も BudouX の発展に期待しています。
3 つ目はウェブサイトのコンテンツの著者の期待通りに改行処理されていない場合にどうするか? BudouX は高い精度で読みやすい単位に改行処理を行ってくれます。しかし、軽量さやスピードを重視しているので、ときには著者が意図する挙動と違う出力をしてしまうことがありました。また、どれだけ高い精度のモデルを採用したとしても、完全自動では 100% 著者の意図通りの結果を出すことは不可能です。どうしてもコンテンツを運用していく中でここだけは間違えてほしくないという場面は存在するわけです。そこで我々は自動+マニュアルの微調整を可能にすることでこれを解決しました。
幸いなことに AEM Franklin にはオーサリング ツールである Google Docs と Microsoft Word のファイルに対してウェブサイトのページごと、またはすべてのページに細かいメタデータを追加する機能が備わっていました。この機能を活用することで、著者が期待するルールや設定を細かく追加できるようになりました。例えば以下のようなことが可能となっています。
この結果 BudouX のスマートな自動改行処理のベネフィットを受けつつ、著者が細かい微調整を加えることを可能にし、理想な運用体制を構築の実現に成功しました。また、現在では移行前の Adobe Experience Manager で管理されているページでも BudouX は活用されており、マニュアルで実施していた改行処理は自動化されています。
BudouX はその軽量さとパフォーマンスが売りです。Lighthouse のスコアへの影響も軽微なもので、adobe.com のパフォーマンス メトリクスをクリアしています。また、最近では finetune が可能になり個別のサイトのコンテンツにあったモデルをより簡単に開発できるようになりました。今後も BudouX の発展に期待しています。
Before
After
現在 BudouX は ICU (International Components for Unicode) の一部になっており、ウェブに限らずさまざまなプラットフォームで利用され始めています。Chrome 119 以降では lang 属性が ja で指定された要素について、CSS で word-break: auto-phrase と指定された部分が BudouX によって分節区切りで折り返されるようになります。Android の文節区切り機能も Android 14 以降では BudouX が使われるようになり、大幅なデータサイズ削減が実現します。さまざまなシーンで読みやすい日本語体験を提供すべく、BudouX はこれからも改善を続けていく予定です。
一方で、BudouX の機械学習モデルも完璧ではなく、うまく処理できないケースもあります。もし、望ましい結果が得られないケースがありましたら、ぜひ GitHub から Issue を立ててください。Pull Request も大歓迎です。皆さまからのフィードバックをお待ちしております。
Shuhei Iitsuka - Senior UX Engineer, Google Brand Studio APACTaketo Yoshida - Software Development Engineer, Adobe Japan R&D
今回は、Maps JavaScript API の読み込み方法に関する 3 つの大きな改善点をご紹介します。3 つの改善点とは、柔軟なライブラリ読み込み用の API、新しいインライン ブートストラップ ローダ、一連のパフォーマンスの向上です。
Maps JavaScript API は、API を読み込むときに開発者が指定して追加できるライブラリで構成されています。これらのライブラリは、ウェブサイト上に地図を表示する以外のことも行います。たとえば、開発者は Places API にアクセスするために、プレイス ライブラリを読み込むことができます。ただし、これらのライブラリの読み込みは柔軟性が低く、これまでは Maps JavaScript API の初期読み込み時にしか指定できなかったため(libraries=places URL パラメータを介するなど)、起動時の読み込みに時間がかかっていました。
そこで、今回、ライブラリを動的にインポートするための API を提供することになりました。たとえば、次のようなものです。
await google.maps.importLibrary("places");
このように定義することで、ユーザーが必要であると判断したときにプレイス ライブラリが読み込みまれるように変更されます。たとえば、ユーザーのアクションの後に、場所に関する情報が必要になった場合です。さらに良いことに、以下のコマンドを介して google.maps.places.Place のような長い名前空間の使用を避けることもできるようになりました。
const {Place} = await google.maps.importLibrary("places");
ただし、google.maps.places 名前空間は引き続き設定されます。
また、複数のライブラリを並行してインポートできるようにもなりました。
const [placesLibrary, geocodingLibrary] = await Promise.all([
google.maps.importLibrary("places"),
google.maps.importLibrary("geocoding")
]);
さらに、ドキュメントに書かれている google.maps.importLibrary() を介して Maps JavaScript API のすべてのクラスを利用できるようにしました。たとえば、ユーザーは次のコマンドを介して StreetViewPanorama クラスにアクセスできます。
const {StreetViewPanorama} = await google.maps.importLibrary("streetView");
これで、Maps JavaScript API の依存関係を読み込むタイミングをより正確かつ効率的に制御できるようになります。
もう一つの問題は、Maps JavaScript API <script> ローダを使用するには、グローバルに定義された関数に対するコールバック パラメータを定義しなければならないことです。現在、開発者の皆様には、API の読み込みを待たずにすぐに google.maps.importLibrary() を使用できる新しいインライン ブートストラップ ローダの使用をおすすめしています。これにより、面倒なグローバル コールバックを回避し、Promises または async/await を使用して、Maps JavaScript API の準備が完了するタイミングを追跡することもできます。
URL で <script> タグを指定する代わりに、ほんの小さなインライン JavaScript である 新しいインライン ブートストラップ ローダを含めることができます。このコードは構成パラメータを受け取り、ブートストラップ URL を構築して、すぐに使用を開始できるように google.maps.importLibrary() を定義します。最初に google.maps.importLibrary() が呼び出されるまで、Maps JavaScript API のどの部分も読み込まれません。この新しいインライン ブートストラップ ローダはページごとに複数回使用することもできます。なお、最初の構成のみが使用されます。また、新しいローダを使用すると、Maps JavaScript API の読み込み時に問題が発生した場合(古いコールバック メカニズムがではサポートしてされていなかったもの)、google.maps.importLibrary() Promise によって適切に拒否されます。
今年は、エンドユーザーの読み込み時間を自動的に短縮できるように、Maps JavaScript API にもいくつかの変更を加えました。静的 JavaScript ファイルの Brotli 圧縮を有効にし、画面外のマップに対して自動遅延読み込みを導入しました。また、今年の後半には、より新しいコードの出力ができるように JavaScript をアップグレードし、より多くのブラウザの組み込み機能を利用してファイルサイズを削減する予定です。
多くの開発者から、なぜ npm 経由で配布しないのかと質問されることがあります。Google は API にアクセスするためのオプションを定期的に評価しており、ほとんどの JS パッケージが npm 経由で配布されている世界では <script> タグが時代遅れに見える可能性があることを十分に認識しています。
Google が得た重要なインサイトに、Maps JavaScript API を採用している多くのウェブサイト(大小問わず)は積極的にメンテナンスされていないというものがあり、Google はこうしたウェブサイトの機能を維持できるようにできる限りのことを行いたいと考えています。UI レンダリングを構成するコードはかなり複雑で、内部で多数のバックエンド サービスを利用します。長年にわたってブラウザやバックエンド サービスに無数の変更が加えられたため、正しい動作を続けるためには、Maps JavaScript API の内部動作を更新する必要がありました。アクセシビリティ、プライバシー、セキュリティに関する重要な更新もありました。また、各ウェブサイトは API を Google から直接読み込むため、こうした更新をすべて自動的に取得できています。積極的に管理されているウェブサイトであっても、Maps JavaScript API を使用する価値の一つは、この種の変更によって引き起こされる予期せぬ破損の多く(およびその結果として生じる、修正を見つけてデプロイするというストレスのかかる作業)を回避できることです。これは、依存関係の管理に取り組む代わりに、自分自身の目標に集中してより多くの時間を費やすことができることを意味します。
<script> の読み込みと npm との間のギャップを埋められるものを探している開発者のために、Google Maps Platform は @googlemaps/js-api-loader パッケージを提供しています。新しい google.maps.importLibrary() は、Loader.importLibrary() を介して js-api-loader とともに使用することもできます。また、Maps JavaScript API の新しいリリースを採用する時期をより細かくコントロールしたいと考えている開発者の方は、利用可能なオプションをご確認ください。Maps JavaScript API の各バージョンは、1 年間利用することができます。
Google Maps Platform に関する詳しい情報はこちらをご覧ください。ご質問やフィードバックはページ右上の「お問い合わせ」より承っております。
Posted by 丸山 智康 (Tomoyasu Maruyama) - Developer Relations Engineer
Google Cloud は、日本時間 11 月 15 日(水)~ 16 日(木)の 2 日間にわたり、旗艦イベント Google Cloud Next Tokyo '23 を東京ビッグサイトにて開催します。今日は、ブレイクアウト セッションについてご紹介します。Next Tokyo では、すべてのブレイクアウト セッションにおいて事前登録が必要です。まずは、こちらから Next へのイベント登録をして、セッション登録へお進みください。
9 つのジャンルに分けて、アメリカの Next で発表された製品の最新情報や、お客様によるクラウド活用事例のセッションをライブでお届けします。スピーカーに直接質問ができる Ask the Speaker コーナーも用意しますので、ぜひ現地でご聴講ください。
人気のセッション、ハンズオン セッションは即時に満席になる場合があります。気になるセッションへは、お早めにご登録されることをお勧めします。
セッション情報の詳細は、以下リンクからチェックできます。
※ Next Tokyo のブレイクアウト セッションのライブ配信はありません。
名称 : Google Cloud Next Tokyo '23(略称 Next Tokyo '23)
日時 : 日本時間 2023 年 11 月 15 日(水) ~ 16 日(木)
会場 : 東京ビッグサイト(東京国際展示場)
対象 : 開発者から CEO まで、クラウド テクノロジーを使ったビジネス課題の解決を探求する、すべての方
ハッシュタグ : #googlecloudnext
Google Cloud Next Tokyo 運営事務局
E-mail: gc-nexttokyo-info@google.com
chrome://flags
chrome://settings/security
編集者注 : この投稿は、世界規模で開催されるインスピレーション、イノベーション、教育に関する展示会「Next '23」から Google Maps Platform に関する最新のニュースをお伝えするシリーズの一部です。Google Maps Platform の新機能の詳細は、8 月 30 日の午前 11 時から 11 時 45 分(米国太平洋夏時間)に行われた「Google Maps Platform の新機能」のセッションでもご覧いただけます。
環境に関して言えば、今は、世代の問題点を明確にし、来るべき世代に影響を与えるべき重要な時期です。環境への影響を軽減する努力を続けることが、これまで以上に重要になっています。私たちが力を合わせれば、より多くの成果が得られます。Google は長年にわたり、地図にできることを進化させてきました。現在は、デベロッパーが Google Maps Platform でできることを拡大し、サステナブルな未来への道を開くエクスペリエンスを構築しています。このたび、Google Maps Platform は、Google Cloud Next '23 に先立ち、新しい Environment API 群(Solar、Air Quality、Pollen)を公開しました。これらの API を使用すると、デベロッパーは絶えず変化する世界をより深く理解できるようになるため、新しいサステナビリティ ツールを作成して、行動につながる分析情報を共有し、環境の新しい現実に適応するよう人々に働きかけられるようになります。
Air Quality API と Pollen API を使用すると、企業は気候変動と環境の変化についての理解を深めることができます。これにより、情報に基づいた選択や、改革の推奨、影響を軽減するための革新的なエクスペリエンスの構築に必要な情報が得られます。また、この情報を利用して、ユーザーがより多くの情報に基づいた意思決定を行えるようにすることもできます。
Air Quality API を使用すると、企業は信頼性の高い大気質データにアクセスして、ヒートマップで汚染を可視化できます。また、汚染物質の詳細情報と推奨される対策を対象ユーザーに提供することもできます。
大気汚染の高い流動性を考慮するため、Google は、政府の観測所、低コストのセンサー、気象データ、衛星、土地被覆、リアルタイムの交通情報など、複数のデータソースからの情報を組み合わせています。この手法では、1 つのデータソースが利用できなくなった場合でも情報を収集できます。Google は、毎時数テラバイトのデータを検証、整理し、地域に固有の信頼性の高い大気質情報を提供します。Air Quality API の詳細については、お知らせのブログ投稿をご覧ください。
Pollen API では、世界中の最も一般的なアレルゲンに関する最新の花粉情報にアクセスできます。Pollen API を使用することで、アレルギーの原因となる花粉にさらされるリスクを抑え、情報に基づいた意思決定を毎日適切に行えるようになります。また、気候が変化するなかで、より長く厳しくなるアレルギーの季節に適応できるようになります。この API は、局所的な花粉の飛散数や植物アレルゲンに関する詳細情報を提供します。ヒートマップによる可視化ができるほか、アレルギー患者が花粉への曝露を最小限にするための実用的なヒントも得られます。花粉と気候の関係を研究している組織や、ユーザーがより健康的な意思決定を行えるように支援したいと考えている企業は、データに基づいた分析情報が得られます。
Pollen API は、世界 65 か国以上の 1 平方キロメートル グリッドにおける花粉の季節性と 1 日あたりの量を計算するモデルを利用しています。また、最大 5 日間の予測、3 種類の植物、15 種類の植物種に対応します。このモデルは、土地被覆、気候データ、植物ごとの年間花粉生成量などのさまざまな入力情報を使用して、地域の花粉飛散量と曝露リスクに関する信頼性の高い予測値を提示します。Pollen API の詳細については、お知らせのブログ投稿をご覧ください。
Google Maps Platform を通じて、環境に関するその他の情報をデベロッパーに提供します。Google は、新しい環境データや、Photorealistic 3D Tiles(間もなくプレビュー版に移行)や Aerial View(一般提供中)などの臨場感あふれるエクスペリエンスを提供するプロダクトへのアクセスを可能にすることで、気候変動に対する革新的なソリューションをサポートする役割を果たしていきたいと考えています。環境データを 3D 画像に重ねて大気質や花粉の飛散量を可視化することは、これらのプロダクトが連携できる方法の一つにすぎません。皆で協力することで、より健康な地球への道を描くことができます。
Google の新しい Environment API 群の詳細については、8 月 30 日の午前 11 時から 11 時 45 分(米国太平洋夏時間)に行われた「Google Maps Platform の新機能」のセッションでもご覧いただけます。
編集者注 : 5 月の I/O で Photorealistic 3D Tiles の試験運用版をリリースして以来、デベロッパーの皆様の関心も高く、このプロダクトに関するデモも紹介されています。また、デベロッパーの皆様から多くのご質問が寄せられています。Cesium のシニア プロダクト マネージャーである Lisa Bos 氏とともに、デベロッパーの皆様から寄せられた最も一般的な質問を取り上げていきます。
Danbi: Photorealistic 3D Tiles のような試験運用フェーズにある Google Maps Platform プロダクトでは、通常はプロジェクトあたりのデフォルトの 1 日の割り当てが低めに設定されています。このフェーズの間は、試験運用しているユースケースに基づいた、お客様からの反応を検証しています。一部のお客様についてはすでに個々のタイル リクエストの割り当て制限が制約になっていることがわかっており、この制限については次のリリース ステージであるプレビューに向けて適切な値となるように再検討しています。
Danbi: Photorealistic 3D Tiles のような試験運用フェーズにある Google Maps Platform プロダクトは、試験運用フェーズの間は無料でご利用いただけますが、上述のように割り当てが制限されています。このリリース フェーズの目的は、プロダクトのプレビュー版をリリースする前にデベロッパーの皆様からのフィードバックを収集することです。皆様からのフィードバック、デモ、ご質問、公開 Issue Tracker は非常に重要ですので、フィードバックをお待ちしております。
ただし、プレビュー期間は通常、プロダクトの料金情報を共有します。このリリース ステージの間、お客様への請求には 100% の割引が適用されます。請求先アカウントをすでに設定している場合、特に操作は必要ありません。お客様の API キーは引き続き機能します。これは、プレビュー版から一般提供に移行するまでに、お客様によるプロダクトと使用量の調整のための期間を設けるためです。
Lisa: デベロッパーの皆様は、Map Tiles API のセッションとリクエストを管理するための周到な戦略を適用したいとお考えでしょう。プレビュー リリース ステージの期間は、CesiumJS やその他の Cesium ランタイムを使用する際に実装の選択がデータ使用量にどのような影響を与えるかを把握できるよう、Cesium がガイダンスをご提供する予定です。提供可能になった時点で、コミュニティ フォーラムでお知らせいたします。
Danbi: Google は、たくさんのデベロッパーの方々がこのプロダクトを試験運用していることを大変喜ばしく思っています。また、適切な権利帰属表示が忘れられがちであることはよく理解しています。しかし、権利帰属表示は Google の利用規約および Map Tiles API ポリシーに明記されているもので、また一般に地図作成における標準的な慣行と考えられています。
重要な権利帰属表示には、ブランド権利帰属表示とデータ権利帰属表示の 2 種類があります。ブランド権利帰属表示では、ビジュアライゼーションに地図や画像を表示するときは常に Google ロゴを表示する必要があります。データ権利帰属表示では、画像の提供元のデータ プロバイダを表示する必要があります。Google マップ アプリケーションを見るとおわかりのように、画像の提供元は Google および他のプロバイダです。ビジュアライゼーションでユーザーが地図上を移動すると、API はビューポートの内容に基づいて、更新されたデータ権利帰属文字列をレンダラに送信します。
権利帰属の表示方法に関するガイドラインをすべてのユースケースに適用できるわけではないことは承知しています。特に、標準または従来の「地図」のビジュアライゼーションとは異なる、映画のようなユーザー エクスペリエンスは権利帰属表示の影響を受けるため、適切でない場合もあります。このような問題に対処するために、Google は、プレビューに移行する際に代替の権利帰属表示方法に関する追加のガイダンスをご提供する予定です。
Lisa: Cesium の各ランタイム(CesiumJS、Cesium for Unity、Cesium for Unreal、Cesium for Omniverse)には、ロゴとデータの権利帰属を表示する方法が用意されています。CesiumJS を使用している場合は、ロゴの追加方法についてこちらをご覧ください。デフォルトでは、ロゴは左下に追加され、データ権利帰属リンクはその右側に表示されます。ロゴと権利帰属表示の配置と外観は、CSS を使用して変更できます。
Danbi: 一般に、3D メッシュモデルの作成には、複数のステレオペア画像を使用した写真測量法によって手続き的に表現されます。メッシュモデル作成には全画素マッチングのような複雑な計算が行われますが、それでも歩行者目線での実世界のモデリングの精度は若干低くなります。たとえば、駐車中の車や日除けがメッシュに溶け込んだり、樹木が浮遊物体としてモデリングされる場合があります。Photorealistic 3D Tiles の改善方法に関するフィードバックをお待ちしています。
Danbi: 現時点で Photorealistic 3D Tiles は「測量グレード」であるとは考えられていません。このプロダクトの本来の目的は、空間分析やモデル測定をサポートすることではなく、臨場感あふれるビジュアライゼーションを実現することです。また、3D 画像からプログラマティックに測定値(高さ、距離、標高など)を読み込んで記録することは派生物と見なされ、禁止されていることにもご注意ください。詳しくは、Google の利用規約に加えて、コンテンツのプリフェッチ、キャッシュ保存、保存に関するポリシーのページをお読みください。このページに、Google の画像データに基づく「画像解析、機械による解釈、オブジェクトの検出 / 識別、地理データの抽出または再販、上述のいずれかを含むオフラインでの使用」は許可されていないと明記されています。
Lisa: デベロッパーの皆様は Cesium を使用して Photorealistic 3D Tiles の現行リリースを他のデータと組み合わせることで、Danbi 氏が上述したようないくつかのユースケースに対応できます。この例では、Photorealistic 3D Tiles によって提供されるコンテキストで精度の高い建築物モデルが可視化されています。お客様自身のメタデータを Cesium アプリに追加して可視化することもできます。簡単な例については、この Cesium Stories チュートリアルをご覧ください。
Danbi: Photorealistic 3D Tiles は現時点では Google の測地系を基にしているため、「測量グレード」と考えられる地理データや、局所的な精度とアライメントの精度が非常に高い地理データの場合、ある程度のずれが生じます。これが、Photorealistic 3D Tiles が現在では測量グレードとは考えられていないもう一つの理由です。しかし、お客様のユースケースにおいて標準測地系とのアライメントがどれだけ重要であるかに関しては、デベロッパーの皆様からのフィードバックをお待ちしています。
Lisa: Photorealistic 3D Tiles と Cesium World Terrain では使用している参照システムが異なるため、現時点では両者を一緒に使用することはおすすめしません。また、その必要もないと思われます。この例に示すように、地球(Cesium World Terrain)を非表示にできます。
Photorealistic 3D Tiles と Cesium を使用するユースケースについて検証する際は、X(旧 Twitter)では @GMapsPlatform、YouTube では @GoogleMapsPlatform、他のチャネルでは #GoogleMapsPlatform のタグをご使用ください。デモギャラリーへの掲載をご希望の場合はお知らせください。
この度、Google Ads API の v 14_1 リリースをお知らせします。v14_1 の一部の機能を使うには、クライアント ライブラリとクライアントのコードをアップグレードする必要があります。更新版のクライアント ライブラリとコードサンプルも公開されました。このバージョンには、互換性のない変更はありません。
主な機能は以下のとおりです。
PerformanceMaxOptInRecommendation
ImprovePerformanceMaxAdStrengthRecommendation
MigrateDynamicSearchAdsCampaignToPerformanceMaxRecommendation
customer_search_term_insight
campaign_search_term_insight
Customer.customer_agreement_setting
AssetGroup
AssetGroupAsset
primary_status
primary_status_reasons
Invoice
AccountSummary
upgraded_targeting
DiscoveryCampaignSettings
true
Discovery
AdType.DISCOVERY_VIDEO_RESPONSIVE_AD
DiscoveryVideoResponsiveAdInfo
以下のリソースが役立ちます。
ご質問やサポートが必要なことがありましたら、フォーラムからご連絡ください。
Posted by Thanet Knack Praneenararat - Ads Developer Relations Team







.png)








