ビデオ会議では、複数のプロセスにまたがるさまざまな処理が動いています。私はいつも数十個のタブを開いています。Chrome のプロセスは 37 個あり、そのうち 6 つがビデオ会議に密接に関連するものでした。さらに、200 個以上の他のプロセスが動作しており(たとえば、svchost.exe は 87 個ありました)、そのうち 4 つがビデオ会議に関連するものでした。2 人の人をつなぐためになぜプロセスが 10 個も必要になるのか、不思議に思う方もいるかもしれません。そこで、使われるプロセスと役割についてまとめてみます。
- audiodg.exe - Windows Audio Device Graph Isolation、オーディオ出力
- dwm.exe - Windows Desktop Window Manager、動画の表示
- svchost.exe - Windows Camera Frame Server(ウェブカメラのキャプチャ)
- System - Windows システム プロセス、各プロセスのためにさまざまなタスクを実行
- chrome.exe - ブラウザのプロセス、マスター コントロール プログラム
- chrome.exe - レンダラ プロセス、Meet タブ
- chrome.exe - GPU プロセス、ページのレンダリングを実行
- chrome.exe - NetworkService ユーティリティ プロセス、ネットワークとの通信
- chrome.exe - VideoCaptureService、Windows Camera Frame Server との通信
- chrome.exe - AudioService、オーディオ入出力のコントロール
セキュリティと安定性を確保するため、これらのタスクは複数のプロセスに分散しています。そのため、いずれかがクラッシュしても、すべてをダウンさせずに再起動できます。また、セキュリティ バグのためにいずれかが侵害されても、システムの他の部分から切り離すことで、被害を抑えることができるかもしれません。
これは妥当なことですが、このように多くのプロセスを扱う場合、パフォーマンスのプロファイリングが難しくなることもあります。すべてのプロセスを確認し、改善の余地がある部分を突き止めるのは困難です。さらに難しいことに、私は Meet のアーキテクチャについてほとんど何も知りません。
プロファイルの分析
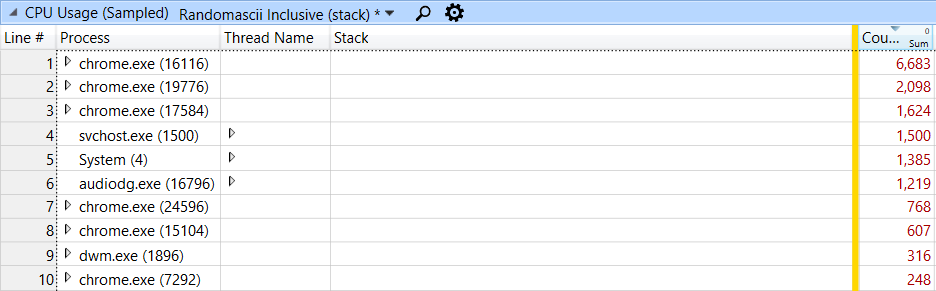
ビデオ会議は CPU を多用します。記録、圧縮、転送、受信、解凍をし、オーディオと動画の両方を出力しなければなりません。下に示すのは、Microsoft の Event Tracing for Windows(ETW)で記録した CPU のサンプルデータです。このサンプリング プロファイラは、すべての実行中のスレッドを 1 秒に約 1,000 回中断させ、コールスタックを記録します。結果の表示には、Windows Performance Analyzer(WPA)を使いました。下のスクリーンショットでは、ビデオ会議に関係する 10 個のプロセスについて、10 秒間にわたって 16,000 以上のサンプル(CPU 時間で約 16 秒)を記録したものを分析しています。
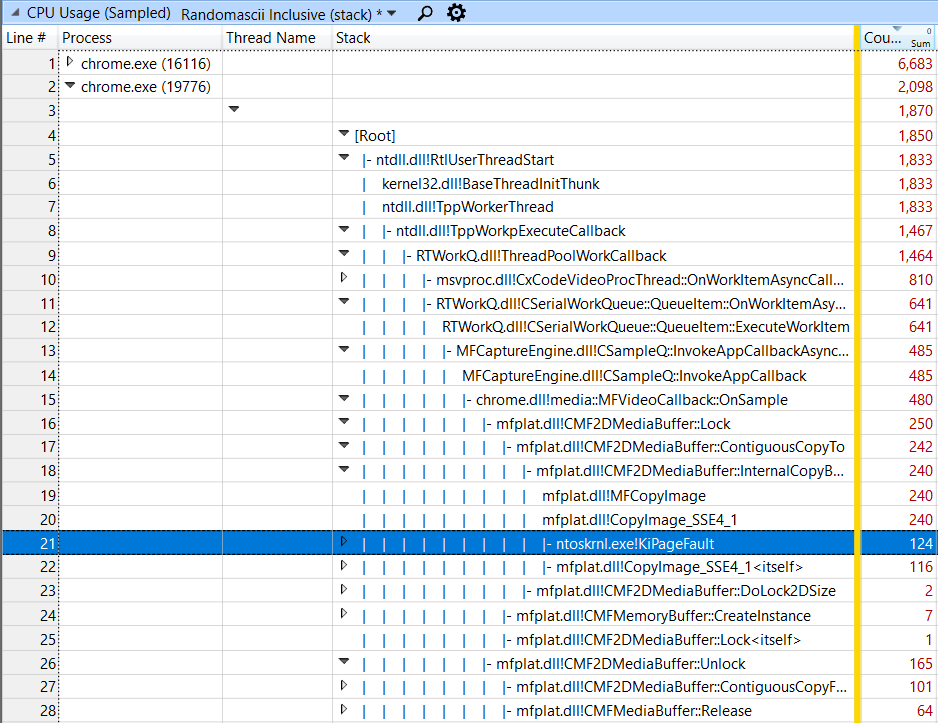
眺めるには数が多すぎるサンプルですが、コールスタックごとにまとまっているので、最も負荷の高いスタックにドリルダウンできます。最初の Chrome プロセスには気になるものはありませんでしたが、2 つ目のプロセスにはありました。
数は多くはありませんが、124 サンプルの KiPageFault は調査する価値があるとすぐにわかりました。このトレースでは、CPU を多用する作業のほとんどが重要で、省くことはできません。しかし、このサンプルは省くことができる作業、すなわち修正できる部分だと直感しました。また、これはサンプル全体のわずか 0.75% にすぎませんが、それよりも大きなコストがかかっている可能性があるとも考えました。
この重要性にすぐに気づくことができたのは、以前に同じような現象を経験していたからです。
KiPageFault は、以前にプロセスに割り当てられていたものの、現在は割り当てられていないメモリにプロセッサがアクセスしたことを示します。これは、メモリを節約するためにページがプロセスから削除されているにもかかわらず、マシンのアクティブなプロセスにはたくさんのメモリがあるということなので、おかしな話です。可能性が高いと思われたのは、最近割り当てられたメモリです。
プログラムが少量のメモリを割り当てる場合、通常はローカルメモリ マネージャー(「ヒープ」と呼ばれることもあります)が保有するメモリがプログラムに渡されます。しかし、適切なメモリブロックがない場合は、オペレーティング システム(OS)にメモリを要求します。プログラムが大量のメモリを割り当てる場合(約 1 MB 以上)、ヒープは確実にメモリを要求します。これ自体は、コストの低いオペレーションです。ヒープは OS にメモリを要求し、OS は「OK」と回答して、このメモリを確保する予定であることを記録するだけです。実際には、このタイミングで OS がプログラムにメモリを提供するわけではありません。Windows、Linux、Android の世界ではそのような仕組みになっています。これは優れた仕組みですが、わかりにくく、意外な動作かもしれません。プロセスがそのメモリにまったくアクセスしない場合、メモリがプロセスに追加されることはありません。しかし、プロセスがメモリにアクセスすると、メモリがゼロで初期化され、個々のページがプロセスに割り当てられます。この動作は、
デマンドゼロ ページ フォールトと呼ばれます。需要が発生したタイミングで「フォールト」が起き、ゼロで初期化されたページがプロセスに渡されるからです。
つまり、大きなメモリブロックの割り当ては非常に安価ですが、確保される予定のメモリが実際に準備されるわけではありません。その後にプログラムがメモリを使おうとし、CPU がそのアドレスにメモリがないことを知ると、CPU は例外を発生させて OS をウェイクアップさせます。OS は記録を確認し、そのアドレスでメモリを確保したことが確認できると、そこにメモリを割り当ててプログラムを再起動させます。この処理は一瞬で終わるので、十分気をつけていないと見逃してしまいます。しかし、プロファイリングをすれば、サンプルに KiPageFault として表示されます。
この奇妙な動作は、4 KiB のブロックが割り当てられるごとに発生します。4 KiB というのは、CPU と OS が扱うページのサイズです。
このコストは少なく、10 秒間で KiPageFault に該当するのは 124 サンプルだけです。つまり、124 ミリ秒(0.124 秒)しかかかっていません。これを包含する CopyImage_SSE4_1 関数の合計コストは約 240 ミリ秒なので、この関数の半分以上がページ フォールトの処理時間であることになりますが、15 行目の OnSample 関数のコストの 4 分の 1 ほどでしかありません。
ページ フォールト自体の合計コストはわずかですが、ここから他の部分でコストが生じていることがうかがえます。
- このメモリが繰り返し(おそらくすべてのフレームで)割り当てられている場合、すべてのフレームで解放する必要もあります。26 行目を見ると、メモリを解放する Release 関数に別の 64 サンプルが使われていることがわかります。
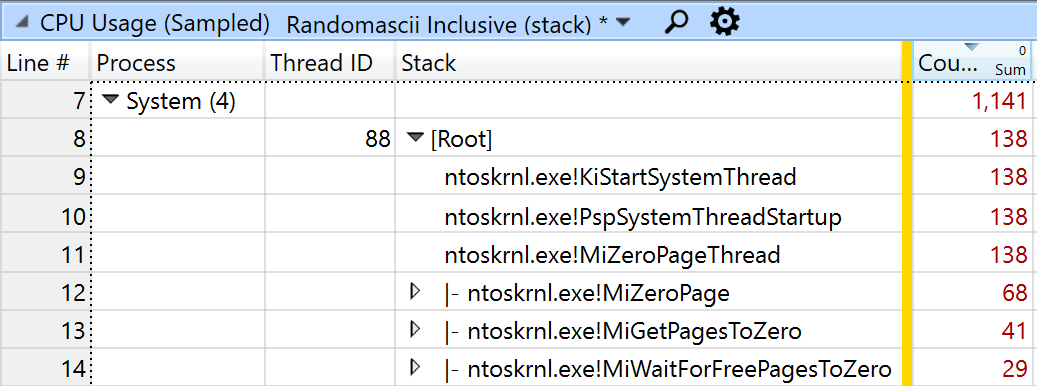
- ページが解放されたとき、オペレーティング システムはそのページを再利用できるように、ゼロで初期化する必要があります(セキュリティ確保のため)。これは Windows System プロセスが行うので、ほぼ完全に見えないコストになります。実際に System プロセスを見てみると、138 サンプルの MiZeroPageThread を確認できます。システム全体の KiPageFault サンプルの 87% が CopyImage_SSE4_1 の呼び出しによるものであることがわかったので、138 サンプルの MiZeroPageThread の 87% がこのパターンによるものと想定されます。
メモリ割り当ての隠れたコストについては、2014 年のブログ投稿で分析しました。Windows の基本的なメモリ アーキテクチャはその後も変わっていないので、隠れたコストは同程度です。
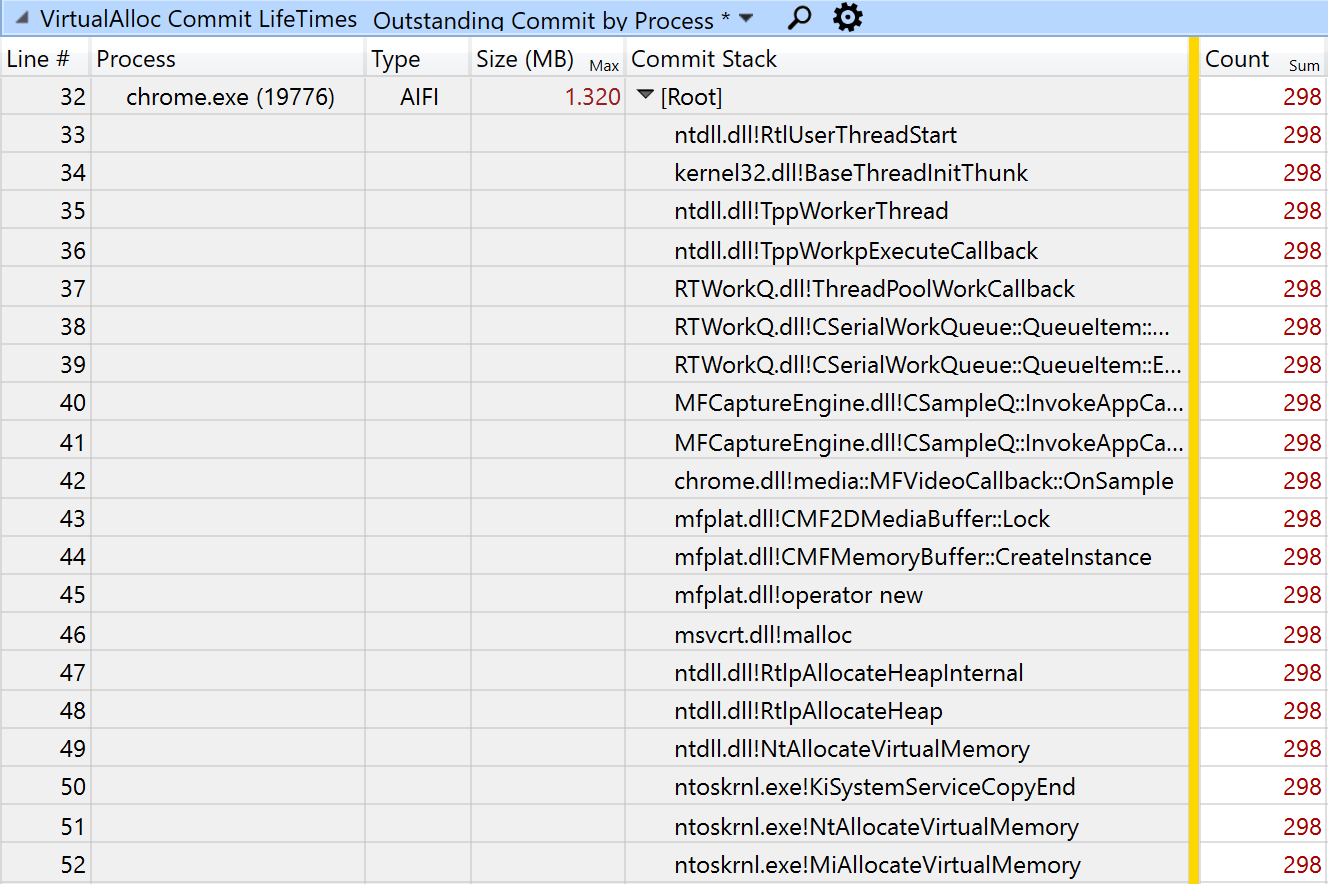
ETW トレースには、CPU のサンプルだけでなく、すべての VirtualAlloc 呼び出しのコールスタックも含まれています。次の WPA のスクリーンショットは、OnSample 関数が 10 秒の間に 1 回あたり 1.320 MB の割り当てを 298 回(1 秒間におよそ 30 回)行っていることを示しています。
現時点で、この割り当ての繰り返しによるコストは、124(フォールトによる読み込み)+64(解放)+124(ゼロで初期化するサンプルの 87%)の合計 312 サンプルと想定されます。これは、ビデオ会議の合計 CPU コストの最大 1.9% になります。これを修正しても世界が変わることはないでしょうが、変更するだけの価値はあります。
その他のコスト
バッファの内容を確認するためにバッファをロックしていますが、実際には、ロック呼び出しによってバッファをコピーすること自体が不要です。ロック呼び出しにやってもらいたいのは、その場所を見ることができるように、バッファの内容を返してもらうことだけです。つまり、MFCopyImage を呼び出すコストがすべて無駄になっていることになります。これで、さらに 116 サンプルが追加されます。加えて、26 行目の CMF2DMediaBuffer::Unlock 呼び出しでは、別の CMF2DMediaBuffer::ContiguousCopyFrom 呼び出しが行われています。これはバッファのコピーが変更されることを想定した処理で、Unlock 呼び出しによって逆方向にコピーしています。そのため、この 101 サンプルも無駄であることがわかります。
割り当て / コピー / コピー / 解放という動作をせずにこのバッファを参照できれば、312 サンプルに加えて、116 サンプル(残りのコピーのコスト)+101 サンプル(逆コピーのコスト)を節約できます。これで節約可能な合計は 3.2% になり、さらなる向上が見込めます。
なお、サンプルデータは統計的にのみ有効なので、実際の割合はコンピュータや細かなワークロードによって大きく異なります。しかし、重要な点は変わりません。劇的ではないものの、調査してみる価値がある変更です。
長年ビデオゲーム業界に関わってきたにもかかわらず、私のグラフィック関係のバッファのロックやアンロックをする API に関する知識は豊富ではありません。最終的にコピーを完全に回避できるという結論にたどりつき、大まかな修正パターンに行き着くには、Twitter フォロワーの皆さんの知恵に頼らざるを得ませんでした。
長文なバグを報告し、実際の修正作業を委任しました。
修正は M85 で実施され、重要性が高いと評価されたため、
M84 にもバックポートされました。
この修正は、Chrome やシステムのさまざまなプロセスにまたがっているので、実際に差を確認するには、かなり細かい注意を払う必要があります。しかし、一部のコンピュータで少しだけ熱くならずに実行できるようになったり、電池が少しだけ長持ちしたりするようになることを期待しています。また、この非効率な処理は Google Meet のプロファイリングによって見つかりましたが、実際には、Chrome(とその他の Chromium ベースのブラウザ)でウェブカメラを使うプロダクトであれば、どのようなものであっても改善の恩恵を受けることができます。
確認
この修正が実施された後、変更の前後の Chrome Canary で、2 つの 10 秒間の ETW トレースを比較してみました。どちらのトレースも、1 つの Chrome タブで Google Meet のミーティング前ページを開く以外、他のプログラムを実行しない状態で取得したものです。また、どちらもプロファイラでの 10 秒間を対象としました。結果は次のようになりました。
OnSample の CPU 時間 :
変更前 : 458 ミリ秒(そのうち 432 ミリ秒が Lock/Unlock/KiPageFault)
変更後 : 27 ミリ秒
割り当て :
変更前 : 1 秒あたり 1.32 MB の割り当てが 30 回(30 fps のフレーム 1 つにつき 1 回。さらに高いフレームレートでは割り当てがさらに多くなる)、10 秒間で合計 396 MB
変更後 : 0 回
System プロセスの MiZeroPageThread の CPU 時間 :
変更前 : 36 ミリ秒
変更後 : 0 ミリ秒
この 3 とおりの測定結果から、パフォーマンスの問題が修正されたことがわかります。OnSample によるメモリのコピーがなくなり、繰り返しの割り当てがなくなり、システム プロセスの作業量も減っています。任務は完了、
バグはクローズです。