新たなウェブ標準である Reporting API は、本番ウェブサイトにアクセスするブラウザで発生する問題をレポートする汎用的な仕組みを提供します。受け取るレポートでは、世界中のユーザーのブラウザで発生するセキュリティ違反やまもなく非推奨になる API などの問題が詳しく説明されています。
多くの場合は、HTTP ヘッダーでエンドポイント URL を指定するだけでレポートを収集できます。するとブラウザは、皆さんにとって関心のある問題が含まれたレポートをエンドポイントに自動転送し始めます。ただし、レポートの処理や分析はそれほど簡単ではありません。たとえば、エンドポイントには大量のレポートが送られてくる可能性がありますが、そのすべてが根本的な問題の特定に役立つわけではない場合があります。そのような状況では、問題を抽出して修正するのは非常に困難かもしれません。
このブログ投稿では、Google セキュリティ チームがどのように Reporting API を使って潜在的な問題を検出し、実際の問題を特定しているかを紹介します。また、Google と同じようなアプローチで簡単にレポートの処理や対策ができるように、オープンソースのソリューションも紹介します。
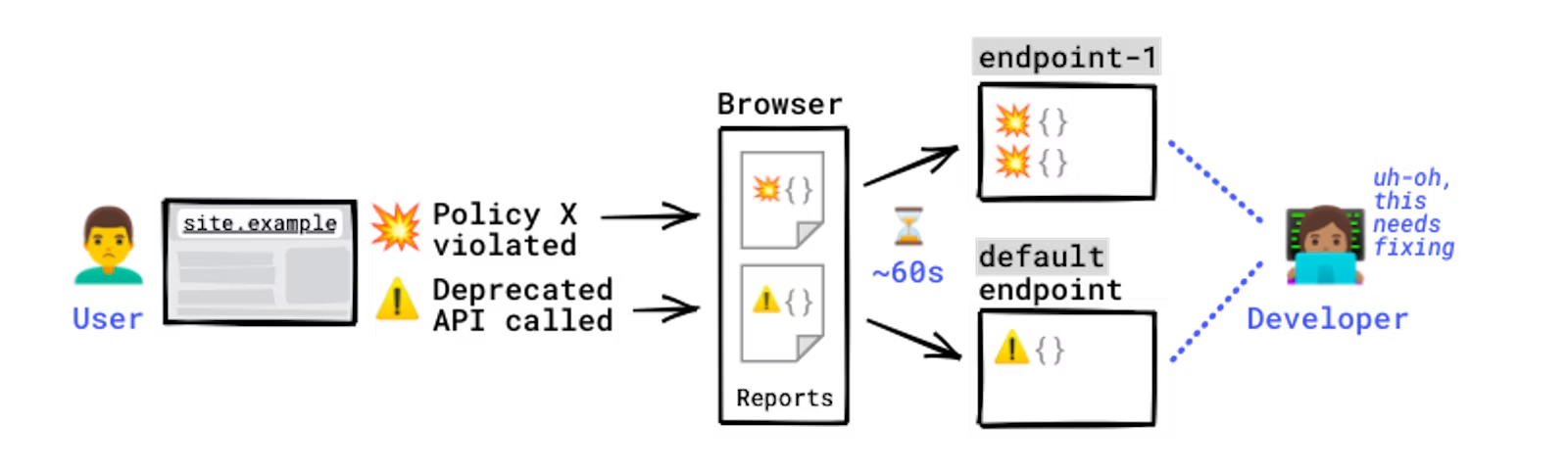
本番環境のユーザーのブラウザでしか発生しないエラーもあります。もちろん、皆さんはユーザーのブラウザにアクセスすることはできません。こういったエラーは、ローカルで、あるいは開発中に見かけることはありません。実際のユーザーやネットワーク、デバイスがどのような状態になっているかわからないからです。Reporting API を使えば、ブラウザを直接利用してこういったエラーをモニタリングできます。つまり、ブラウザがエラーをキャッチし、エラーレポートを生成して、指定したエンドポイントに送信してくれます。
レポートの生成と送信の仕組み。
Reporting API でモニタリングできるエラーには、次のようなものがあります。
# CSP 違反レポート、Document-Policy 違反レポート、非推奨レポートを受け取る設定の例 Reporting-Endpoints: main-endpoint="https://reports.example/main", default="https://reports.example/default" # CSP 違反と Document-Policy 違反を `main-endpoint` に送信するContent-Security-Policy: script-src 'self'; object-src 'none'; report-to main-endpoint; Document-Policy: document-write=?0; report-to=main-endpoint; # 非推奨レポートは自動生成され、明示的なエンドポイントは必要ない。常に `default` エンドポイントに送信される
DevTools の [Application] パネルに表示されるレポートの例。
レポートのエンドポイントのデモでは、生成されたさまざまな違反がサーバーでどのように受信されるかを確認できます。
違反レポートの例
2024 年 3 月時点で、Chrome は Reporting API をサポートしており、Safari は一部をサポートしています。詳細については、ブラウザ サポートの表をご覧ください。
Google は、セキュリティを大規模に向上できるという恩恵を受けています。Content Security Policy、Trusted Types、Fetch Metadata、Cross-Origin Opener Policy といったウェブ プラットフォームによる対策は、さまざまな Google プロダクトや無数の個々のサービスからあらゆる脆弱性を排除するために役立ちます。この点は、こちらのブログ投稿で詳しく説明しています。
Reporting API では、1 つのレポート エンドポイントと、複数のセキュリティ機能を表現する 1 つのスキーマを使ってこのサイクルを実行できます。そのため、ブラウザ、コードパス、ユーザータイプを問わずに、さまざまな機能のレポートを一元的に収集できます。
注 : ポリシーで禁止されているアクションを行おうとすると、違反レポートが生成されます。たとえば、あるページに CSP を設定しているにもかかわらず、CSP で許可されていないスクリプトを読み込もうとする場合です。Reporting API で生成されるレポートのほとんどは違反レポートですが、それがすべてではありません。その他のタイプには、非推奨レポートやクラッシュ レポートなどがあります。詳細については、ユースケースとレポートタイプをご覧ください。
残念ながら、違反レポートのストリームにはノイズが紛れ込むことがよくあります。その場合、準拠していないコードを見つけることが難しくなる可能性があります。たとえば、多くのブラウザ拡張機能、マルウェア、ウィルス対策ソフトウェア、開発ツールのユーザーは、DOM にサードパーティのコードを挿入したり、禁止された API を使ったりしています。挿入されるコードがポリシーに準拠していない場合、コードベースにリンクされていない対策不可能な違反レポートになる可能性があります。そのため、レポートのトリアージが困難になり、すべてのコードを確実に準拠させてから新しいポリシーを適用するのが難しくなります。
Google は長年にわたり、違反レポートを収集して活用し、それをまとめて 根本原因に集約するための多くの技術を開発してきました ここでは、デベロッパーが違反レポートのノイズを除外できる技術の中から、特に役立つ技術の概要を紹介します。
ブラウザのタブが使われている間に、ポリシーに準拠していないコードが何度も実行されることはよくあります。それが発生するたびに、新しい違反レポートが作成され、キューイングされて、レポートのエンドポイントに送信されます。これが起きると、冗長な情報を含む大量のレポートができてしまいます。そこで、違反レポートをクラスタにグループ化することで、個々の違反を意識することなく、根本原因について考えることができます。根本原因の方が理解しやすいので、有効なリファクタリング方法を探す時間を短縮できます。
例を通して、違反がどのようにグループ化されるのかを確認してみましょう。たとえば、インライン JavaScript イベント ハンドラの使用を禁止する report-only の CSP が導入されているとします。違反レポートは、該当するハンドラのすべてのインスタンスについて作成され、次のフィールドが設定されます。
blockedURL
inline
scriptSample
documentURL
ほとんどの場合、この 3 つのフィールドで、特定の URL のインライン ハンドラを一意に識別できます。他のフィールドの値が異なる場合でも同様です。こういったことがよく起こるのは、トークンやタイムスタンプなどのランダムな値をページをまたいで使う場合です。前述のようなフィールドの値は、アプリケーションやフレームワークによって微妙に異なる場合があるため、レポート値をあいまい一致させることができれば、手間を省きつつ、違反をクラスタにグループ化して対策につなげることができます。必要に応じて、URL フィールドに既知のプレフィックスがある違反をグループ化することができます。たとえば、URL が chrome-extension、moz-extension、safari-extension で始まるすべての違反をグループ化すると、根本原因がコードベース以外のブラウザ拡張機能である違反を、高い信頼性で特定できます。
chrome-extension
moz-extension
safari-extension
対策不可能な違反レポートと対策可能な違反レポートを区別するもう 1 つの方法が、環境情報です。このデータは、レポートのエンドポイントへのリクエストには含まれますが、違反レポート自体には含まれません。環境情報からクライアント設定におけるノイズ源を判別できる可能性があるので、トリアージに役立つかもしれません。
違反のタイプによっては、source_file フィールドまたはそれと同等のフィールドが含まれます。このフィールドは、違反の原因となった JavaScript ファイルを表し、通常は行番号と列番号が付いています。これらの 3 ビットデータは高品質の信号であり、リファクタリングが必要なコードの行を直接指すことができます。
source_file
ただし、コンパイルや最小化のために、ブラウザがフェッチしたソースファイルがコードベースに直接マッピングできなくなることもよくあります。その場合は、JavaScript ソースマップを使って、デプロイされたファイルとオーサリングされたファイルの間で行番号と列番号をマッピングするとよいでしょう。すると、違反レポートがソースコードの行に直接変換されるので、非常に対策しやすいレポート グループと根本原因が生成されます。
Reporting API は、セキュリティ違反、非推奨の API 呼び出し、ブラウザの介入などのブラウザ側イベントを、イベントごとに指定されたエンドポイントに送信します。ただし、前のセクションで説明したように、そのレポートから実際の問題を抽出するには、データ処理システムが必要です。
ブラウザからレポートを受け取る方法と、受け取ったレポートを処理する方法を理解できるように、小さなサンプル アプリケーションを作成しました。このアプリケーションで、ブラウザが送信したレポートからウェブ アプリケーションのセキュリティ問題を抽出するために必要なプロセスを示します。具体的には、以下のプロセスになります。
緑色のボックスは、独自に実装する必要があるコンポーネントです。 フォワーダ(forwarder) はシンプルなウェブサーバーであり、JSON 形式のレポートを受け取り、それを Bigtable 用のスキーマに変換します。 ビームコレクタ(beam-collector) はシンプルな Apache Beam パイプラインであり、ノイズの多いレポートをフィルタリングし、関連するレポートを集約して、CSV ファイルとして保存します。この 2 つのコンポーネントは、Reporting API からのレポートを有効利用するうえで重要な役割を果たしています。
ここで共有したオープンソース ソリューション以外にも、Reporting API を簡単に使えるようにするツールがいくつも用意されています。次のようなものがあります。
この記事では、ウェブ デベロッパーが Reporting API を使ってクライアント側の問題を収集する方法と、収集したレポートから実際の問題を抽出する際の課題について説明しました。また、その課題を解決するために Google がどのようにレポートをフィルタリングして処理しているかを説明し、同様のソリューションを実現する際に利用できるオープンソース プロジェクトを紹介しました。この情報が役立ち、Reporting API を活用するデベロッパーが増え、結果としてウェブサイトの安全性と持続可能性が向上することを願っています。