ユーザーはウェブをブラウジングするときに、さまざまな脅威に遭遇します。誤認させるサイトや偽物のサイトにパスワードなどのプライベートな情報を入力するように欺かれる場合があり、これはフィッシングとも呼ばれます。マルウェアと呼ばれる悪意のあるソフトウェアをインストールさせられ、個人データを収集されたり、身代金を要求されたりすることもあります。Google Chrome(以降は Chrome と記述します)は、このようなインターネット上の脅威からユーザーを守ります。Chrome ユーザーがセーフ ブラウジング保護をオンにしてウェブをブラウズすると、Chrome は Google のセーフ ブラウジング サービスを使ってさまざまな脅威を特定して回避します。
セーフ ブラウジングは、ユーザーの設定によって動作が異なります。特に一般的なのは、Chrome がセーフ ブラウジング サービスのプライバシーに配慮した Update API(アプリケーション プログラミング インターフェース)を使うケースです。この API はユーザーのプライバシーを念頭に置いて開発され、Google は可能な限り最小のユーザーの閲覧履歴しか取得しない仕組みになっています。ユーザーが [保護強化機能](以前の投稿で取り上げました)や [検索とブラウジングを改善する] をオンにしている場合、Chrome はユーザーの保護を強化することのみを目的として、一部の追加データをセーフ ブラウジングと共有します。
この投稿では、Update API の技術的な実装や詳しいプライバシー配慮の仕組みを適宜示しながら、Chrome の Update API の実装方法について説明します。ここで紹介する内容は、セーフ ブラウジングによってどのように保護されているかをユーザーが理解したり、興味があるデベロッパーが実装を参照したりする際に役立つはずです。保護強化機能に使われる API については、今後の投稿で取り上げたいと思います。
インターネット上の脅威
ユーザーがインターネット上のウェブページを開くと、ブラウザがインターネット上のホストに保存されているオブジェクトを取得します。こういったオブジェクトには、ウェブページの構造(HTML)、スタイル設定(CSS)、ブラウザの動的な動作(Javascript)、イメージ、操作によって始まるダウンロード、メインページに埋め込まれた他のウェブページなどがあります。これらはリソースとも呼ばれ、URL(Uniform Resource Locator)と呼ばれるウェブアドレスが割り当てられています。また、URL が読み込まれると、別の URL にリダイレクトされることもあります。そういったそれぞれの URL に、フィッシング サイト、マルウェア、望まないダウンロード、悪意のあるソフトウェア、不正な課金などの脅威が潜んでいる可能性があります。Chrome でセーフ ブラウジングをオンにすると、URL、リダイレクト、インクルードされるリソースのすべてがチェックされるので、そのような脅威を特定してユーザーを保護できます。
セーフ ブラウジング リスト
セーフ ブラウジングは、脅威からユーザーを守るため、インターネット上の脅威のリストを提供します。Chrome が使う完全なリストは、PC プラットフォームから chrome://safe-browsing/#tab-db-manager にアクセスすると参照できます。
リストには安全でないウェブの完全なアドレス(URL とも呼ばれます)は含まれていません。デバイスの限られたメモリにすべてを保持するのは、あまりに高価すぎて不可能だからです。URL は非常に長くなる可能性があるので、暗号ハッシュ関数(SHA-256)によって URL を固定長の一意な文字列にマッピングします。この固有の固定長文字列はハッシュと呼ばれ、これを使って限られたメモリにリストを効率的に格納します。Update API はハッシュ形式でのみ URL を扱うため、この投稿ではハッシュベース API と呼んでもいいでしょう。
さらに、リストには完全なハッシュが保存されているわけでもありません。この方法でも、メモリを使いすぎてしまうからです。実際には、データを Google と共有しない場合やリストが小さい場合を除き、ハッシュのプレフィックスのみを保持しています。ここでは、オリジナルのハッシュを完全ハッシュ、ハッシュのプレフィックスを部分ハッシュと呼びます。
リストは Update API のリクエスト頻度セクションの内容に従って更新されます。失敗のレスポンスを受け取った場合、Chrome はバックオフ モードにも従います。このアップデートは、サーバーが設定したリスト更新レスポンスの最小待機時間に従って、およそ 30 分ごとに行われます。
関連するソースコードに興味がある方のために、閲覧すべき場所をお知らせします。
ソースコード
- GetListInfos() には、すべてのリストに加えて、関連する脅威の種類、使われているプラットフォーム、ディスク上のファイル名が含まれます。
- HashPrefixMap はリストの格納方法とメンテナンス方法を示します。二分探索ベースの高速な検索ができるように、リストはプレフィックス長でグループ化されたうえで連結されます。
ハッシュベースの URL 検索の仕組み
セーフ ブラウジング リストの例として、マルウェア用のリストがあるとします。ここには、マルウェアをホストしている URL の部分ハッシュが含まれています。通常、部分ハッシュの長さは 4 バイトですが、説明のため、ここでは 2 バイトのみを表示します。
['036b', '1a02', 'bac8', 'bb90']
ある URL に移動したときなど、Chrome が Update API でリソースの評判を確認するときは、検索をするためにセーフ ブラウジングに未加工の URL(やその一部)を提示することはありません。Chrome は URL(と URL の組み合わせ)の完全ハッシュを使い、ローカルに保持されているセーフ ブラウジング リストの部分ハッシュを検索します。そして、一致した部分ハッシュのみをセーフ ブラウジング サービスに送信します。このようにすることで、Chrome はプライバシーを尊重しながらユーザーを確実に保護します。このハッシュベースの検索は、以下の 3 ステップで行われます。
ステップ 1: URL の組み合わせと完全ハッシュを生成する
Google は、セーフ ブラウジング リストに登録することで、安全でない可能性があるリソースをホストする URL をブロックします。すると、悪意のある人物は、そのリソースを別の URL にホストするかもしれません。または、さまざまなサブドメインを使い回して新しい URL を作るかもしれません。セーフ ブラウジングはホストのサフィックスを使い、サブドメインにマルウェアをホストしている悪意のあるドメインを特定します。同様に、悪意のある人物はさまざまなサブパスも使い回して新しい URL を作るかもしれません。そこで、セーフ ブラウジングはパスのプレフィックスも使って、さまざまなサブパスにマルウェアをホストするウェブサイトを特定します。これにより、悪意のある人物がサブドメインやパスを使い回して悪意のある URL を新たに作ることを防げるので、確実かつ効率的に脅威を特定できます。
ホストのサフィックスとパスのプレフィックスに対応するため、Chrome はまず URL の完全ハッシュと、URL から算出できるいくつかのパターンを計算します。Chrome は、セーフ ブラウジング API の URL とハッシュの仕様に従い、以下の手順によって URL の組み合わせの完全ハッシュを計算します。
- まず、Chrome は URL を仕様で定義されている正規形に変換します。
- 次に、その URL に対して最大 5 つのホストのサフィックス / バリアントを生成します。
- 次に、その URL に対して最大 6 つのパスのプレフィックス / バリアントを生成します。
- 次に、その 30 個のホストのサフィックスとパスのプレフィックスの組み合わせのそれぞれについて、完全ハッシュを生成します。
ソースコード
- V4LocalDatabaseManager::CheckBrowseURL はハッシュベースの検索を行う例です。
- V4ProtocolManagerUtil::UrlToFullHashes は、ある URL に対してさまざまな URL の組み合わせを作成し、それらの完全ハッシュを計算します。
例
たとえば、ユーザーが https://evil.example.com/blah#frag にアクセスしようとしているとします。正規化した URL は、https://evil.example.com/blah です。試すべきホストのサフィックスは evil.example.com と example.com です。パスのプレフィックスは / と /blah です。4 つの URL の組み合わせは、evil.example.com/、evil.example.com/blah、example.com/、example.com/blah です。
url_combinations = ["evil.example.com/", "evil.example.com/blah","example.com/", "example.com/blah"]
full_hashes = ['1a02…28', 'bb90…9f', '7a9e…67', 'bac8…fa']
ステップ 2: ローカルリストで部分ハッシュを検索する
次に Chrome は、URL の組み合わせの完全ハッシュと、ローカルに保持されているセーフ ブラウジング リストを照合します。このリストには部分ハッシュしか含まれていないので、悪意があると決定的に判定することはできません。しかし、URL に悪意がないと考えられるかどうかはすばやく特定できます。URL の完全ハッシュがローカルのリストのどの部分ハッシュとも一致しなければ、URL は安全であると考えられ、Chrome は読み込み処理に進みます。チェックされる URL の 99% 以上がこの手順に従います。
ソースコード
- V4LocalDatabaseManager::GetPrefixMatches は、URL とその組み合わせの完全ハッシュに一致する部分ハッシュを取得します。
例
3 つの完全ハッシュ 1a02…28、bb90…9f、bac8…fa が、ローカルの部分ハッシュに一致することがわかります。これはデモ目的であり、実際にここで一致が起きることはほとんどありません。
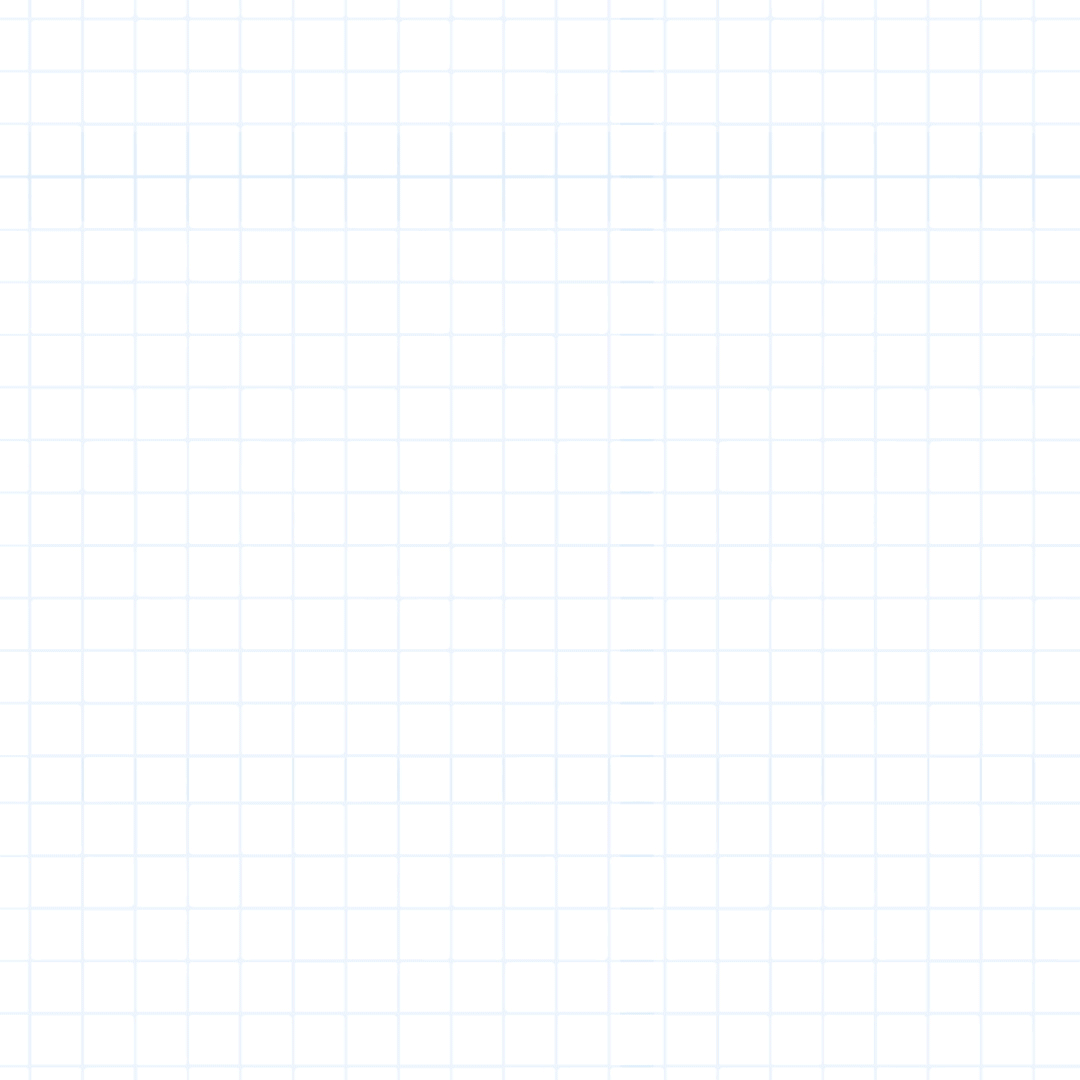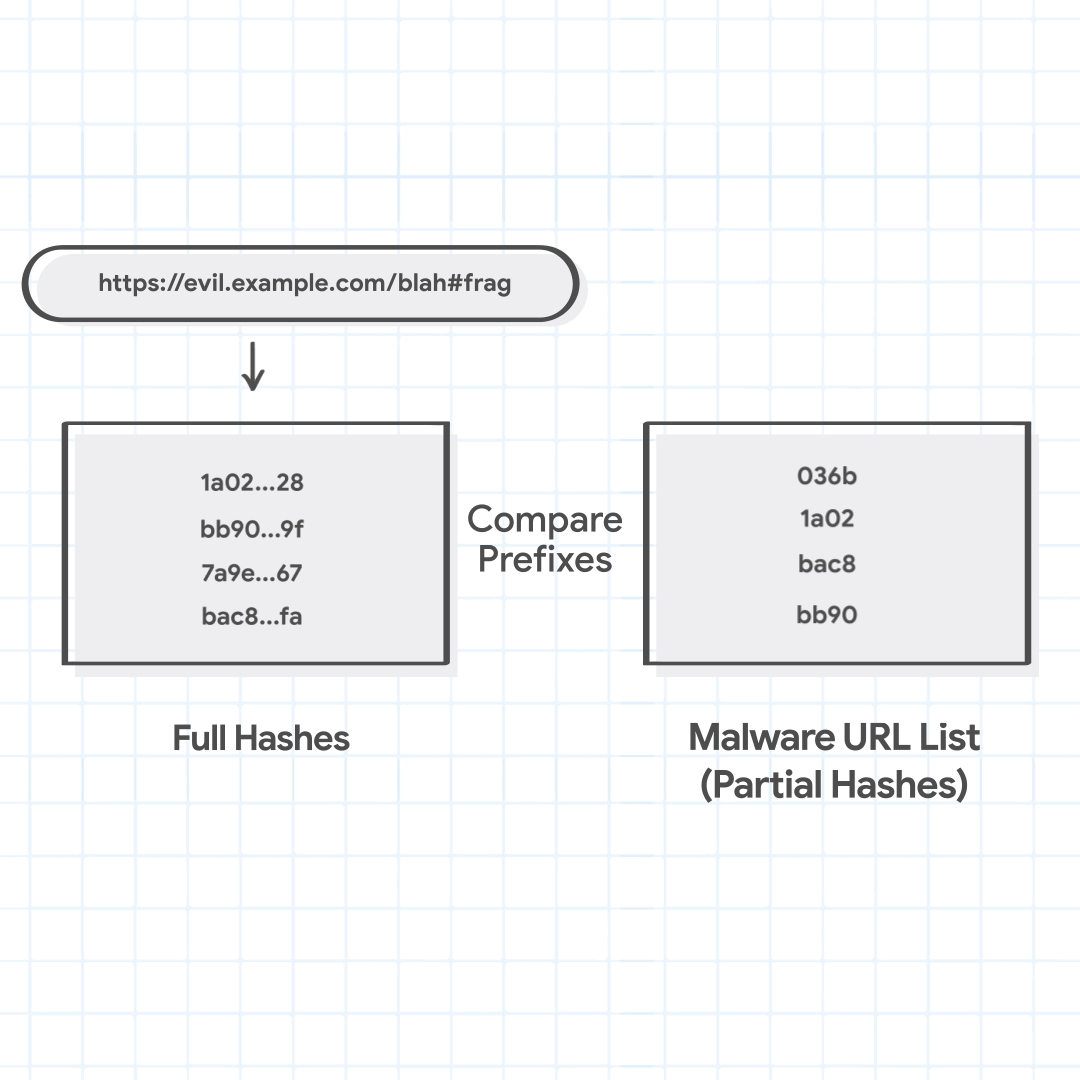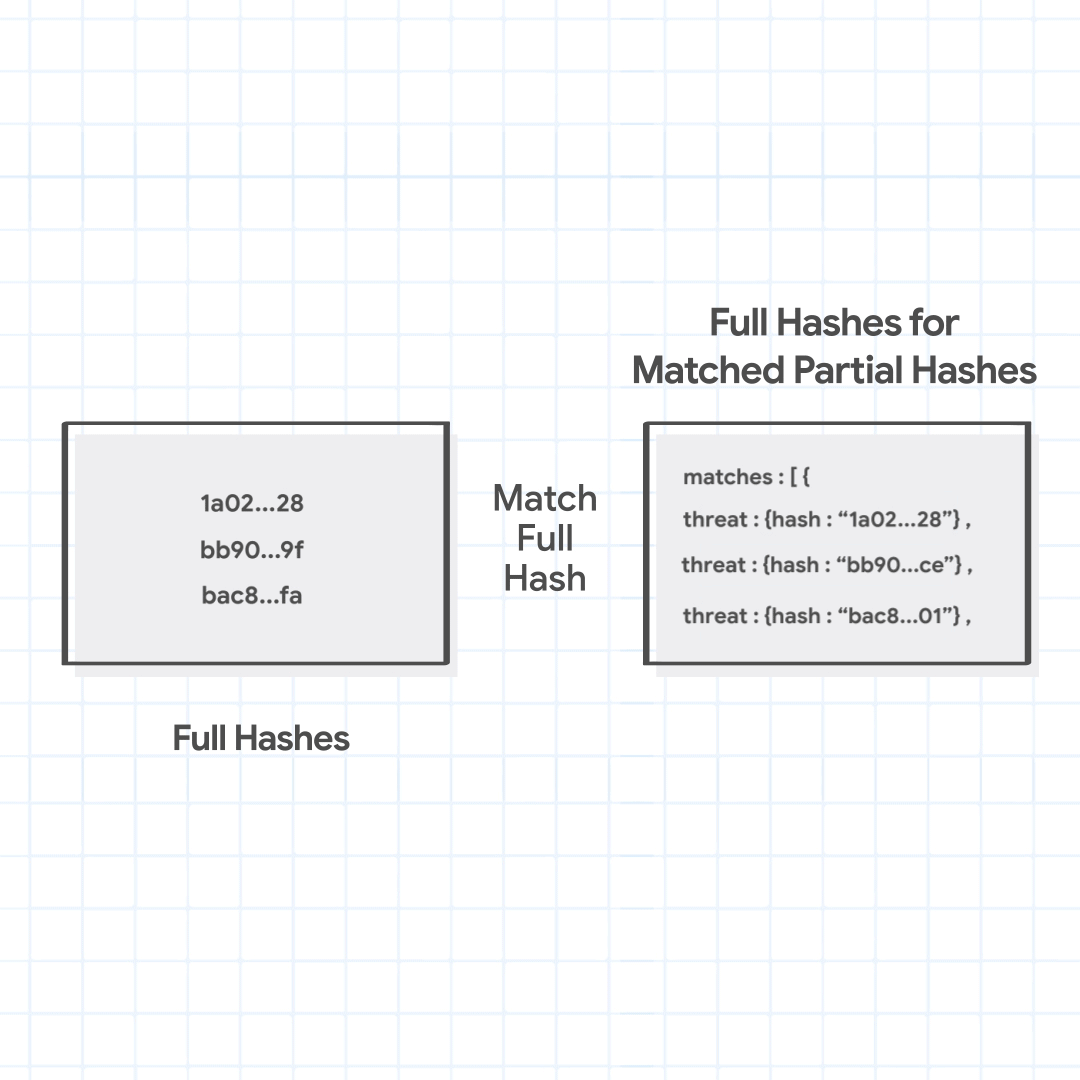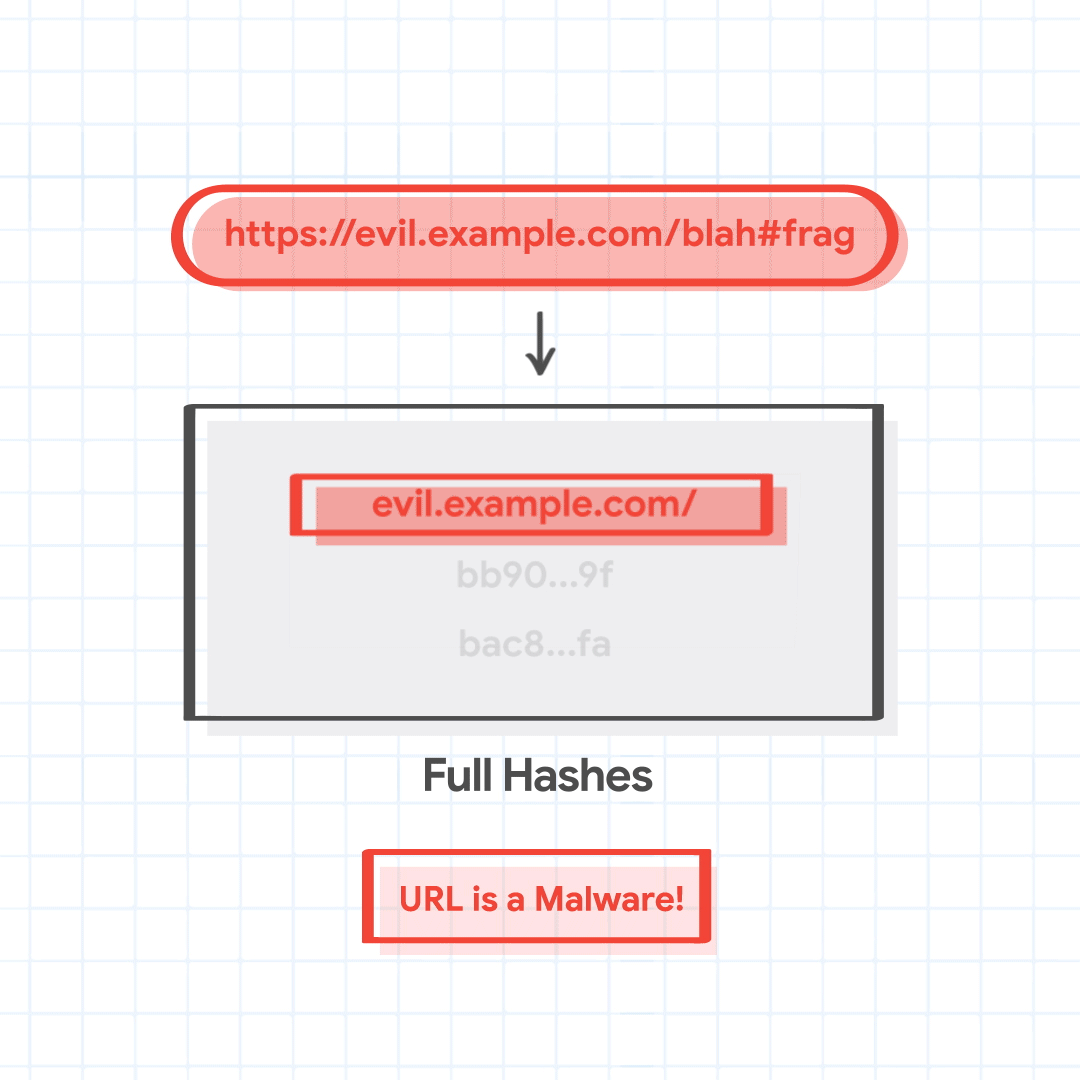
ステップ 3: 一致する完全ハッシュを取得する
次に Chrome は、セーフ ブラウジング サービスの fullHashes.find メソッドに、一致した部分ハッシュのみを送信します(完全な URL や URL の一部、その完全ハッシュは送信しません)。その応答として、すべての悪意のある URL の完全ハッシュが返されます。この完全ハッシュは、Chrome が送信した部分ハッシュのいずれかで始まるものです。Chrome は、取得した完全ハッシュと、URL の組み合わせから生成した完全ハッシュを照合します。一致する場合、その URL は完全ハッシュに対応したさまざまな脅威や重大度を持つ URL であると特定されます。
ソースコード
- V4GetHashProtocolManager::GetFullHashes は一致した部分ハッシュに対応する完全ハッシュを検索します。
例
Chrome は一致した部分ハッシュ 1a02、bb90、bac8 を送信し、完全ハッシュを取得します。サーバーは部分ハッシュに一致する完全ハッシュとして、1a02…28, bb90…ce, と bac8…01 を返します。完全ハッシュの 1 つがチェック対象の URL の組み合わせの完全ハッシュと一致するので、Chrome はこの URL がマルウェアをホストする悪意のある URL であると特定します。
まとめ
セーフ ブラウジングは、インターネット上のさまざまな悪意や脅威から Chrome ユーザーを守ります。これらの保護を提供する一方で、Chrome はメモリ容量の制約、ネットワーク帯域幅の使用量、ダイナミックな脅威の状況といった課題に直面します。さらに、ユーザーのプライバシーの選択にも配慮し、Google と共有するデータを可能な限り少なくしています。
今後の投稿では、Chrome が [保護強化機能] をオンにしたユーザーに提供する高度な保護について説明したいと思います。


