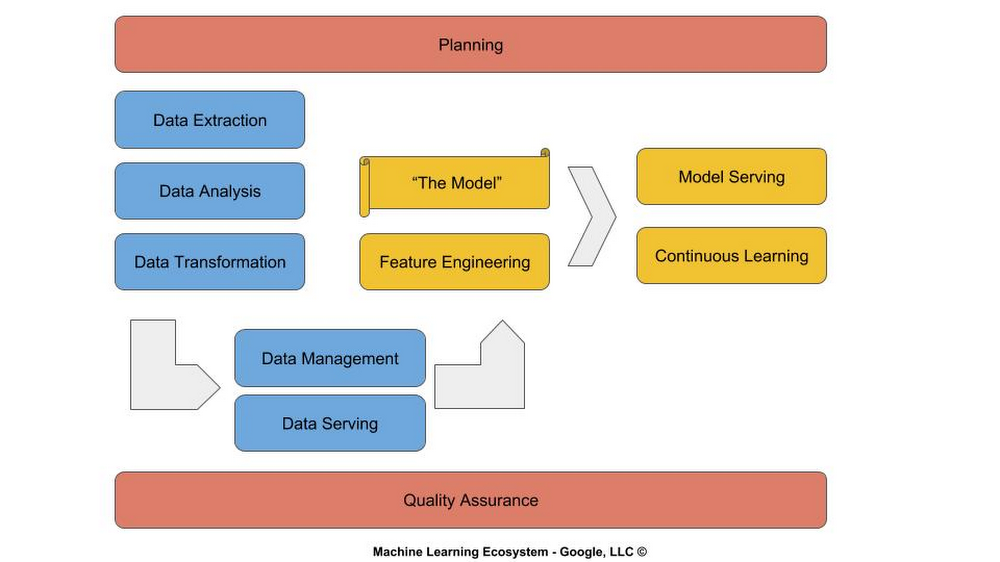
機械学習ライフサイクルは、主に 3 つのフェーズ、プラニング(赤)、データ エンジニアリング(青)、モデリング(黄)で構成されています。
プランニング
ML モデルは、ソフトウェア デベロッパーがコーディングする静的アルゴリズムとは違い、学習によって動的に更新されるアルゴリズムです。ソフトウェア アプリケーションは、計画されたタスクを実行するアルゴリズムの集合体と考えることができます。アルゴリズムはデザイン パターンによって定義され、ソフトウェア エンジニアがコーディングを行います。アプリケーションが本番環境にリリースされても、計画どおりに動作するとは限りません。その場合、デベロッパーは再検討、再設計、再コーディングを行います(継続的インテグレーションや継続的デリバリー)。
現在は、こういった静的アルゴリズムの一部を ML モデルで置き換える時代に突入しつつあります。ML モデルは、本質的に動的なアルゴリズムです。しかし、動的であるがゆえに、プロダクトのオーナーや品質管理(QA)チームと連携して作業する企画担当者には、たくさんの新しい問題が降りかかることになります。
たとえば、QA チームは指標のテストや報告をどのように行えばよいのでしょうか。多くの場合、ML モデルは、信頼度スコアで表現されます。評価用のデータセットに対して、97% の精度を示すモデルがあったとしましょう。これは品質テストに合格するでしょうか。静的アルゴリズムを使って計算機を作成し、97% の確率で正解が得られた場合、私たちは正解を返さない 3% について知りたいと考えるはずです。
また、毎日朝のミーティングでは、機械学習モデルをどのように扱えばよいでしょうか。毎朝、トレーニング プロセスが昨日学んだことや今日学ぶはずのことを報告してくれるとは思えません。データの収集やクリーニング、ハイパーパラメータのチューニングについて、チームが報告する方が現実的でしょう。
アプリケーションがリリースされてサポートが始まると、通常は、ユーザーの問題に対応するためのポリシーを作成します。しかし、継続的学習や強化学習を行う場合、モデルはポリシーを学習しています。では、どのようなポリシーを学習させたいでしょうか。たとえば、状況を観察して、ユーザー インターフェースのナビゲーションにストレスを感じているユーザーを検知してもらい、そのストレスを減らすためにインターフェースを適応させる方法(自動 A/B)を学習させたいと考えることもできるでしょう。
効率的な ML ライフサイクルでは、ここで挙げたような組織に固有の問いに答え始めるために、すべてのステージでプラニングを行わなければなりません。
データ エンジニアリング
データ エンジニアリングは、開発予算の大半が消化される部分です。組織によっては、その額はエンジニアリング費用の 70% から 80% になります。学習はデータに依存するので、たくさんの適切なデータが必要になります。古くからのソフトウェア エンジニアリングの格言にあるように、ガラクタを入れれば、ガラクタが出てくるものです。モデリングにも、同じことが言えます。つまり、悪いデータを入れれば、モデルが学習するのはノイズです。
実際に必要になるのは、ソフトウェア エンジニアやデータ サイエンティストだけでなく、データ エンジニアリング組織です。こういった有能なエンジニアたちは、データ収集(例: 数十億件のレコード)、データ抽出(例: SQL、Hadoop)、データ変換、データ保管、データ提供などを行います。物理リソース(永続ストレージやコンピューティング)の大半を消費するのは、データです。通常は、データの規模の大きさから、従来型のオンプレミス手法ではなくクラウド サービスで処理が行われます。
データ操作(DataOps)に熟練した人々は、データクラウドのデプロイや管理を効率的に行うことができます。データ収集やデータ提供を行うのは、データ ウェアハウジングに熟練した人々(DBA)です。データ抽出やデータ変換はデータ エンジニアリングに熟練した人々(データ エンジニア)が、データ分析は統計分析や視覚化に熟練した人々(データ アナリスト)が行います。
モデリング
モデリングは、ソフトウェア開発ライフサイクル全体に組み込まれます。1 回だけモデルをトレーニングしてそれで終わりというわけにはいきません。ワンショット トレーニングという考え方は、予算やシンプルさの面で魅力的ではあるものの、学術的なユースケースやシングルタスクのユースケースにしか効果はありません。
モデリングは、ごく最近までデータ サイエンティストの領域でした。初期の ML フレームワーク(Theano や Caffe など)は、データ サイエンティスト用に設計されたものでした。ML フレームワークは進化しており、現在はどちらかと言えばソフトウェア エンジニアの領域となっています(Keras や PyTorch など)。データ サイエンティストは、機械学習アルゴリズムやその集合体の分類についてのリサーチ、ビジネスのポリシーや方向性の助言、データ主導型チームを主導する役割への移行において、重要な役割を果たしています。
しかし、ML フレームワークや AI as a Service(AIaaS)が進化しているので、モデリングの大半はソフトウェア エンジニアが行うようになるでしょう。現在はデータ エンジニアが行っている特徴エンジニアリングについても、同じことが言えます。データ オントロジー、名前空間、自己定義スキーマ、インターフェース間の取り決めに関して従来のタスクとの類似性を考えれば、特徴エンジニアリングもソフトウェア エンジニアリングの領域へ移ることになるでしょう。また、多くの組織は、モデルの構築やトレーニングをクラウドベースのサービスに移行することになるでしょう。クラウドのサービスは、ソフトウェア エンジニアがデータ操作によって管理することができます。その後のモデリングは、AIaaS のさらなる進化に合わせて、
Cloud Vision や
Cloud Speech-to-Text のようにクラウド API からアクセスしてすぐ使うことができるソリューションの組み合わせや、AutoML などの転移学習ツールを使ってトレーニング済みのアルゴリズムをカスタマイズする作業に変わるはずです。
Keras や PyTorch などのフレームワークは、既に
シンボル プログラミングから
命令型プログラミング(ソフトウェア開発で主流になっている形態)に移行しており、継承、カプセル化、ポリモーフィズムなどのオブジェクト指向プログラミング(OOP)原理を取り入れています。 その他の ML フレームワークも進化して、データベースでは既に使われているオブジェクト リレーショナル モデル(ORM)がデータソースや推論(予測)にも含まれるようになるはずです。一般的なベスト プラクティスも進化し、Gang of Four の
デザイン パターンが OOP の進化に影響を与えたように、業界全体のデザイン パターンが定義されて公開されるようになるでしょう。
継続的インテグレーションや継続的デリバリーと同じように、継続的学習もビルドプロセスに移動し、ビルドや信頼性を担当するエンジニアが管理するようになります。その後、アプリケーションがリリースされると、実環境での利用や適応によって新しい洞察がデータという形式で生成され、モデルが継続的に学習できるように、モデリング プロセスにフィードバックされます。
もうお分かりだと思いますが、機械学習の採用は、モデルのトレーニング方法を学習するだけで済むような単純なものではありません。ML モデルが既存のシステムやプロセスにどのように当てはまるかについて深く考え、適切にスタッフを教育しなければなりません。私を含め、すべての Google のスタッフは、機械学習に対応できるようにソフトウェア開発ライフサイクルをアップグレードする皆さんに、機械学習へ向かう最高の道のりを歩んでいただきたいと願っています。Google Cloud で機械学習について詳しく学びたい方は、
Cloud AI プロダクトページをご覧ください。