BudouX は、ウェブをはじめさまざまなプラットフォームで読みやすいテキスト折り返し(改行)を実現するための、軽量な分かち書き器です。オープンソース プロジェクトとして GitHub で公開されており、現時点では日本語と中国語(簡体字、繁体字)をサポートしています。2016 年に公開した Budou の後継となるものですが、Budou とは違いサードパーティの API や分かち書きライブラリに依存せずに動作します。分かち書きのための機械学習モデルを含めて 20 KB 程度に収まるため、ウェブブラウザに配信する JavaScript ファイルに同梱することも可能です。
単語と単語の間をスペースで空けて書く英語などの言語と異なり、日本語や中国語をはじめとするアジア圏の一部の言語は分かち書きをしません。そのため、ウェブサイトやモバイル アプリケーションで日本語や中国語を表示する際に、スクリーンサイズによって好ましくない折り返しが起きてしまうことがあります。このような問題の解決策として、改行要素や改行可能要素を挿入する、特定の要素の折り返しを禁止するなどの方法が考えられます。しかし、そのいずれも対象言語に精通した人物による手作業が必要になるため、大量のテキストがある場合に対応するのは困難です。
この問題を自動で解決するために開発されたのが、BudouX です。BudouX は文字の N グラムに対して AdaBoost アルゴリズムを適用した機械学習モデルを利用しています。この機械学習モデルはテキスト中の各文字について、次の文字の間で区切るべきか否かの二値分類問題を考えます。予測値が正であれば区切り、そうでなければ区切らないという処理を繰り返すことで、読みやすく分かち書きされたテキストを出力します。
特徴量として文字の N グラム(特定の文字が連続して出現するまとまり)のみを使うため、任意の言語に対してモデルを学習、適用できます(Language Neutral)。また、AdaBoost アルゴリズムによって、読みやすい折り返しに強く寄与する N グラムから順に重みを割り当て、それ以外の特徴量は無視できるため、機械学習モデルの軽量化が可能です(Small)。BudouX では JSON シリアライズされた機械学習モデル、すなわち N グラムと重みのペアをデコードして、現れた N グラムに対応する重みの値を足し合わせるだけで予測値が得られます。したがって JSON パーサと基本的な処理構文さえあれば実行できるため、さまざまなプログラミング言語やプラットフォームに容易に拡張することができます(Standalone)。BudouX はこのように Small, Standalone, Language Neutral の 3 つを基本的な方針として開発を進めています。
日本語のデフォルトの分かち書きモデルは、単語単位ではなく文節単位の分ち書きを提供します。これは文節間の改行が日本語の読みやすさに寄与すると考えているためです。このモデルの学習には主に KNB コーパス(Kyoto-University and NTT Blog コーパス)による文節区切りの文章を用いています。モデル訓練の詳細については BudouX scripts README をご覧ください。
現在、BudouX の公式レポジトリでは JavaScript, Python, Java をサポートしています。それぞれの使い方を簡単に紹介します。
JavaScript
NPM を使う場合、BudouX の JavaScript モジュールは npm i budoux としてインストールできます。日本語のデフォルトの分かち書き器を使う場合は、下記のようにしてパーサを読み込み、処理したい文字列をその parse メソッドに渡します。結果は分かち書きされた文字列の配列が渡されます。
import { loadDefaultJapaneseParser } from 'budoux' ; const parser = loadDefaultJapaneseParser(); console.log(parser.parse('今日は天気です。')); // ['今日は', '天気です。']
NPM を使わず、ウェブブラウザ上で下記のように ES Module として直接読み込むことも可能です。ここではビルドされたモジュールをホストするサイトとして unpkg.com を使用した例を示します。
<script type="module"> import {loadDefaultJapaneseParser} from 'https://unpkg.com/budoux/module/index.js'; const parser = loadDefaultJapaneseParser(); console.log(parser.parse('今日は天気です。')); // ['今日は', '天気です。'] </script>
ウェブでの利用を目的としている場合は、Web Components 版も利用可能です。まずウェブページ内で、下記のようにして BudouX カスタム要素を読み込みます。ここでは例として日本語モデル(budoux-ja)を読み込んでいます。
<script src="https://unpkg.com/budoux/bundle/budoux-ja.min.js"></script>
その後、BudouX により折り返し処理を適用したい文字列を budoux-ja カスタム要素に渡すと、自動でテキスト折り返しを整えるためのマークアップが Shadow Root に挿入されます。
<budoux-ja>今日は天気です。</budoux-ja>
<!-- Shadow Root -->
<span style="word-break: keep-all; overflow-wrap: anywhere;">今日は<wbr>天気です。</span>
Python
BudouX モジュールは、 pip install budoux としてインストールできます。以下に、Python で日本語モデルを読み込み、分かち書きを行う例を示します。
import budoux
parser = budoux.load_default_japanese_parser()
print(parser.parse('今日は天気です。')) # ['今日は', '天気です。']
Java
BudouX モジュールは Maven Central Repository にて com.google.budoux として公開されています。インストール後、以下のようにして日本語モデルを利用できます。
import com.google.budoux.Parser;
public class App {
public static void main(String[] args ){
Parser parser = Parser.loadDefaultJapaneseParser();
System.out.println(parser.parse("今日は天気です。"));
// ["今日は", "天気です。"]
}
BudouX はプレーンテキストだけではなく、HTML コードに対しても適用可能です。より進んだ使い方について詳しくは BudouX レポジトリの README をご覧ください。
ここからは、BudouX をご活用いただいているアドビの Japan R&D に所属する Software Development Engineer の吉田さんに活用の経緯などをお伺いしました。
どこで BudouX を活用している?
自社のオウンドメディアである adobe.com の日本語サイトにて BudouX を活用しています。適切な改行処理を行うことでデバイスサイズに限らずに読みやすい日本語になるように工夫しています。
BudouX を活用しているページの例
https://www.adobe.com/jp/acrobat/online/ppt-to-pdf.html https://business.adobe.com/jp/resources/main.html https://business.adobe.com/jp/customer-success-stories.html
BudouX を活用に至るまでの経緯
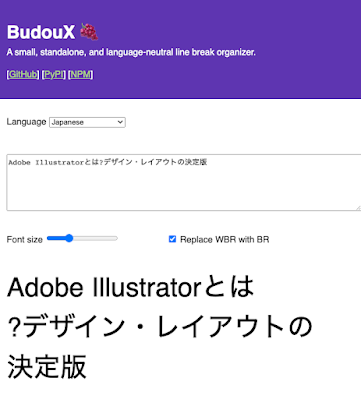
実は BudouX 採用前からアドビでは日本語の改行処理に力を入れていました。adobe.com は自社製品の CMS、Adobe Experience Manager 上で構築されていますが、ページを編集する際に区切り文字をマニュアルで入れることで著者が改行ポイントを設定することができました。我々は以前から日本語における適切な改行処理に関心があったというわけです。 話は本題へと移ります。現在 adobe.com は Adobe Experience Manager で構築された従来のサイトから、次世代のアドビの CMS 製品である AEM Franklin をベースにしたサイトへの移行プロジェクトを実施しています。AEM Franklin では Google Docs や Microsoft Word をオーサリング ツールとして活用することができます、また、Adobe Experience Manager で課題であった複雑なシステム構成やウェブサイトのパフォーマンスなどを容易に改善することができる等、新しいコンセプトの製品となっています。 しかし AEM Franklin をベースとした新しい製品を活用したウェブサイトへの移行となったため、今まで存在していた編集時の日本語の改行処理の機能がなくなってしまいました。このような状況の中で、この問題の解決のためにさまざまな手法を検討し、実装コストや運用コストなどを考慮した結果、サーバーサイドで分かち書きなどの前処理するのではなく、クライアントサイドだけで軽量に動作する BudouX がベストだという結論に至り、採用することとなりました。 それでも導入の際には 3 つ課題がありました。1 つ目は BudouX の日本語のデフォルト モデルはアドビのコンテンツを学習していません。特に「お、ご、などの尊敬語に弱い」、「デジタルエクスペリエンスプラットフォームなどの長いカタカナの複合名詞」は精度の面でやや不安があったわけです。そこで新たに adobe.com のデータをスクレイピングし学習させることでよりアドビのサイトにあったモデルを開発することができました。詳しい話はこちらの記事で書かれているので興味がある方はご覧ください。 2 つ目は禁則処理の問題です。禁則処理とは行頭や行末に特定の文字が来ないように文字の並びを調整する処理を指します。例えば、句読点は行頭には来ないようにするなどが挙げられます。BudouX は次の文字の間で区切るべきか否かの二値分類問題を考えています。その結果、かなり低確率ではありますが、周辺文字の状況によって句読点の前で文字が区切られてしまう例がわずかに見られました。我々が普段 HTML で文章を書いているときはブラウザが自動で日本語の禁則処理をしてくれるので問題ありませんが、BudouX では改行ポイントを <wbr> でコントロールしているので、例えば以下の画像のように行頭に疑問符(半角)が来てしまいます。この問題を解決するために、我々はルールベースの禁則処理を BudouX に追加することで禁則処理を実現しました。なお、この問題は現在 BudouX の GitHub にイシューとして登録しています。
実は BudouX 採用前からアドビでは日本語の改行処理に力を入れていました。adobe.com は自社製品の CMS、Adobe Experience Manager 上で構築されていますが、ページを編集する際に区切り文字をマニュアルで入れることで著者が改行ポイントを設定することができました。我々は以前から日本語における適切な改行処理に関心があったというわけです。
話は本題へと移ります。現在 adobe.com は Adobe Experience Manager で構築された従来のサイトから、次世代のアドビの CMS 製品である AEM Franklin をベースにしたサイトへの移行プロジェクトを実施しています。AEM Franklin では Google Docs や Microsoft Word をオーサリング ツールとして活用することができます、また、Adobe Experience Manager で課題であった複雑なシステム構成やウェブサイトのパフォーマンスなどを容易に改善することができる等、新しいコンセプトの製品となっています。
しかし AEM Franklin をベースとした新しい製品を活用したウェブサイトへの移行となったため、今まで存在していた編集時の日本語の改行処理の機能がなくなってしまいました。このような状況の中で、この問題の解決のためにさまざまな手法を検討し、実装コストや運用コストなどを考慮した結果、サーバーサイドで分かち書きなどの前処理するのではなく、クライアントサイドだけで軽量に動作する BudouX がベストだという結論に至り、採用することとなりました。
それでも導入の際には 3 つ課題がありました。1 つ目は BudouX の日本語のデフォルト モデルはアドビのコンテンツを学習していません。特に「お、ご、などの尊敬語に弱い」、「デジタルエクスペリエンスプラットフォームなどの長いカタカナの複合名詞」は精度の面でやや不安があったわけです。そこで新たに adobe.com のデータをスクレイピングし学習させることでよりアドビのサイトにあったモデルを開発することができました。詳しい話はこちらの記事で書かれているので興味がある方はご覧ください。
2 つ目は禁則処理の問題です。禁則処理とは行頭や行末に特定の文字が来ないように文字の並びを調整する処理を指します。例えば、句読点は行頭には来ないようにするなどが挙げられます。BudouX は次の文字の間で区切るべきか否かの二値分類問題を考えています。その結果、かなり低確率ではありますが、周辺文字の状況によって句読点の前で文字が区切られてしまう例がわずかに見られました。我々が普段 HTML で文章を書いているときはブラウザが自動で日本語の禁則処理をしてくれるので問題ありませんが、BudouX では改行ポイントを <wbr> でコントロールしているので、例えば以下の画像のように行頭に疑問符(半角)が来てしまいます。この問題を解決するために、我々はルールベースの禁則処理を BudouX に追加することで禁則処理を実現しました。なお、この問題は現在 BudouX の GitHub にイシューとして登録しています。
3 つ目はウェブサイトのコンテンツの著者の期待通りに改行処理されていない場合にどうするか? BudouX は高い精度で読みやすい単位に改行処理を行ってくれます。しかし、軽量さやスピードを重視しているので、ときには著者が意図する挙動と違う出力をしてしまうことがありました。また、どれだけ高い精度のモデルを採用したとしても、完全自動では 100% 著者の意図通りの結果を出すことは不可能です。どうしてもコンテンツを運用していく中でここだけは間違えてほしくないという場面は存在するわけです。そこで我々は自動+マニュアルの微調整を可能にすることでこれを解決しました。 幸いなことに AEM Franklin にはオーサリング ツールである Google Docs と Microsoft Word のファイルに対してウェブサイトのページごと、またはすべてのページに細かいメタデータを追加する機能が備わっていました。この機能を活用することで、著者が期待するルールや設定を細かく追加できるようになりました。例えば以下のようなことが可能となっています。 " ご覧ください " というテキストがあったときに " ご " と " 覧ください " の間では改行できないようにする " カスタマージャーニーマップ " というテキストがあったときに " カスタマー " と " ジャーニーマップ " の間で改行できるようにする ページの一部分に BudouX を適用しないようにする BudouX に渡すパラメータを調整する この結果 BudouX のスマートな自動改行処理のベネフィットを受けつつ、著者が細かい微調整を加えることを可能にし、理想な運用体制を構築の実現に成功しました。また、現在では移行前の Adobe Experience Manager で管理されているページでも BudouX は活用されており、マニュアルで実施していた改行処理は自動化されています。 BudouX はその軽量さとパフォーマンスが売りです。Lighthouse のスコアへの影響も軽微なもので、adobe.com のパフォーマンス メトリクスをクリアしています。また、最近では finetune が可能になり個別のサイトのコンテンツにあったモデルをより簡単に開発できるようになりました。今後も BudouX の発展に期待しています。
3 つ目はウェブサイトのコンテンツの著者の期待通りに改行処理されていない場合にどうするか? BudouX は高い精度で読みやすい単位に改行処理を行ってくれます。しかし、軽量さやスピードを重視しているので、ときには著者が意図する挙動と違う出力をしてしまうことがありました。また、どれだけ高い精度のモデルを採用したとしても、完全自動では 100% 著者の意図通りの結果を出すことは不可能です。どうしてもコンテンツを運用していく中でここだけは間違えてほしくないという場面は存在するわけです。そこで我々は自動+マニュアルの微調整を可能にすることでこれを解決しました。
幸いなことに AEM Franklin にはオーサリング ツールである Google Docs と Microsoft Word のファイルに対してウェブサイトのページごと、またはすべてのページに細かいメタデータを追加する機能が備わっていました。この機能を活用することで、著者が期待するルールや設定を細かく追加できるようになりました。例えば以下のようなことが可能となっています。
この結果 BudouX のスマートな自動改行処理のベネフィットを受けつつ、著者が細かい微調整を加えることを可能にし、理想な運用体制を構築の実現に成功しました。また、現在では移行前の Adobe Experience Manager で管理されているページでも BudouX は活用されており、マニュアルで実施していた改行処理は自動化されています。
BudouX はその軽量さとパフォーマンスが売りです。Lighthouse のスコアへの影響も軽微なもので、adobe.com のパフォーマンス メトリクスをクリアしています。また、最近では finetune が可能になり個別のサイトのコンテンツにあったモデルをより簡単に開発できるようになりました。今後も BudouX の発展に期待しています。
Before
After
現在 BudouX は ICU (International Components for Unicode) の一部になっており、ウェブに限らずさまざまなプラットフォームで利用され始めています。Chrome 119 以降では lang 属性が ja で指定された要素について、CSS で word-break: auto-phrase と指定された部分が BudouX によって分節区切りで折り返されるようになります。Android の文節区切り機能も Android 14 以降では BudouX が使われるようになり、大幅なデータサイズ削減が実現します。さまざまなシーンで読みやすい日本語体験を提供すべく、BudouX はこれからも改善を続けていく予定です。
一方で、BudouX の機械学習モデルも完璧ではなく、うまく処理できないケースもあります。もし、望ましい結果が得られないケースがありましたら、ぜひ GitHub から Issue を立ててください。Pull Request も大歓迎です。皆さまからのフィードバックをお待ちしております。
Shuhei Iitsuka - Senior UX Engineer, Google Brand Studio APACTaketo Yoshida - Software Development Engineer, Adobe Japan R&D